Tomcat关键知识了解
Tomcat 是由 Apache 软件基金会 开发的一个开源的 Java Web 应用服务器,属于 Jakarta 项目的核心部分。它支持最新的 Servlet 和 JSP 规范,能够运行基于 Java 的动态 Web 应用程序。
关键文件及目录说明
tomcat源码目录说明
在apache的tomcat官网下载的tomcat9源码中,可以看到如下的目录:
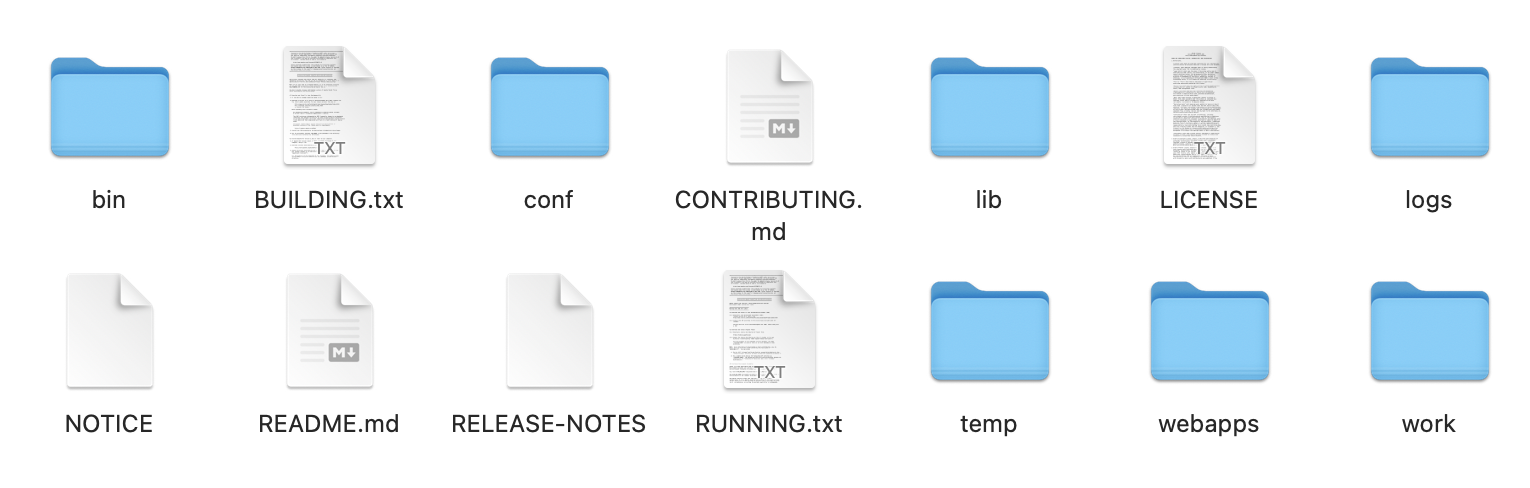
有几个关键的目录需要说明:
/bin:启动、关闭和其他脚本,在linux中就是使用startup.sh文件来启动tomcat,windows则是startup.bat功能副本。/conf:配置文件和相关的DTD。里面有两个重要的文件,server.xml和web.xml,两个配置文件定义了非常多的运行策略,比如server.xml就定义了tomcat对外暴露的端口,而web.xml就定义了将*.jsp的交给jsp引擎解析等策略。/logs:默认情况下,日志文件位于此处。/webapps:这是Web应用程序所在的位置。/lib:存放一些需要的jar包依赖资源。
由此基本了解了一个tomcat的基本目录结构。
web应用程序目录说明
我们可以先在idea上搭建一个tomcat用来编辑一个web程序的源码,可以参考我之前的文章:
https://fupanc-w1n.github.io/p/tomcat%E6%90%AD%E5%BB%BA%E6%95%99%E7%A8%8B/
现在来看web应用程序下的目录布局,需要知道如下的一些信息:
*.html、*.jsp等:HTML和JSP页面,以及应用程序中客户端浏览器必须可见的其他文件(例如 JavaScript、样式表文件和图像)。在较大的应用程序中,你可以选择将这些文件划分为子目录层次结构,但对于较小的应用程序,通常只需为这些文件维护一个目录即可。/WEB-INF/web.xml:应用程序的Web 应用程序部署描述符,这是一个非常重要的配置文件,描述构成应用程序的 servlet 和其他组件,以及你希望服务器为你强制执行的任何初始化参数和容器管理的安全约束。/WEB-INF/classes/:应用程序所需的Java类文件,也就是我们后端实现的包括路由等的一些功能实现的java文件。/WEB-INF/lib/:此目录包含JAR文件,也就是当前应用程序所需第三方类库。
基本信息如上,其下还有两个点需要说明:
- idea中的tomcat的实现逻辑:其实就是相当于直接在tomcat的webapps目录下编写文件,然后经过一些调用从而成功启动tomcat容器。
- /WEB-INF/web.xml文件说明:在前面我们了解到了tomcat的
/conf目录下也会存在一个web.xml文件。这两个文件有什么区别和联系呢,根据我的理解,/conf目录下的web.xml配置文件对全局的环境设置起作用,而一个tomcat可以有多个应用程序,不可能每一个web应用程序的filter、servlet配置那些都是一样的,故需要在各自的WEB-INF目录下存放一个web.xml配置文件来定义各自需要的配置,并且只会在自己的应用程序中生效。
tomcat架构学习
关于tomcat架构的知识点以及简单的jsp技术可以参考我之前的tomcat内存马文章的基础知识板块的知识点:
https://fupanc-w1n.github.io/p/tomcat%E5%86%85%E5%AD%98%E9%A9%AC/
权限设置
来看看tomcat的一些权限设置方法。
账密+web.xml+jsp
最常见的就是用户名登陆,在简单了解下,我们可以通过配置tomcat的user配置文件来进行用户设置,比如如下过程设置:
先在tomcat源码的conf目录下往tomcat-users.xml文件中添加如下内容:
1
|
<user username="admin" password="123456" roles="manager-gui"/>
|
设置了一个用户名和密码,需要配合web.xml来进行规则匹配,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<security-constraint>
<web-resource-collection>
<web-resource-name>Admin Pages</web-resource-name>
<!-- 限制 admin/ 目录下所有 JSP -->
<url-pattern>/admin/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<!-- 只有 manager-gui 用户才能访问 -->
<role-name>manager-gui</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>FORM</auth-method>
<form-login-config>
<form-login-page>/login.jsp</form-login-page>
<form-error-page>/login_error.jsp</form-error-page>
</form-login-config>
</login-config>
<security-role>
<role-name>manager-gui</role-name>
</security-role>
</web-app>
|
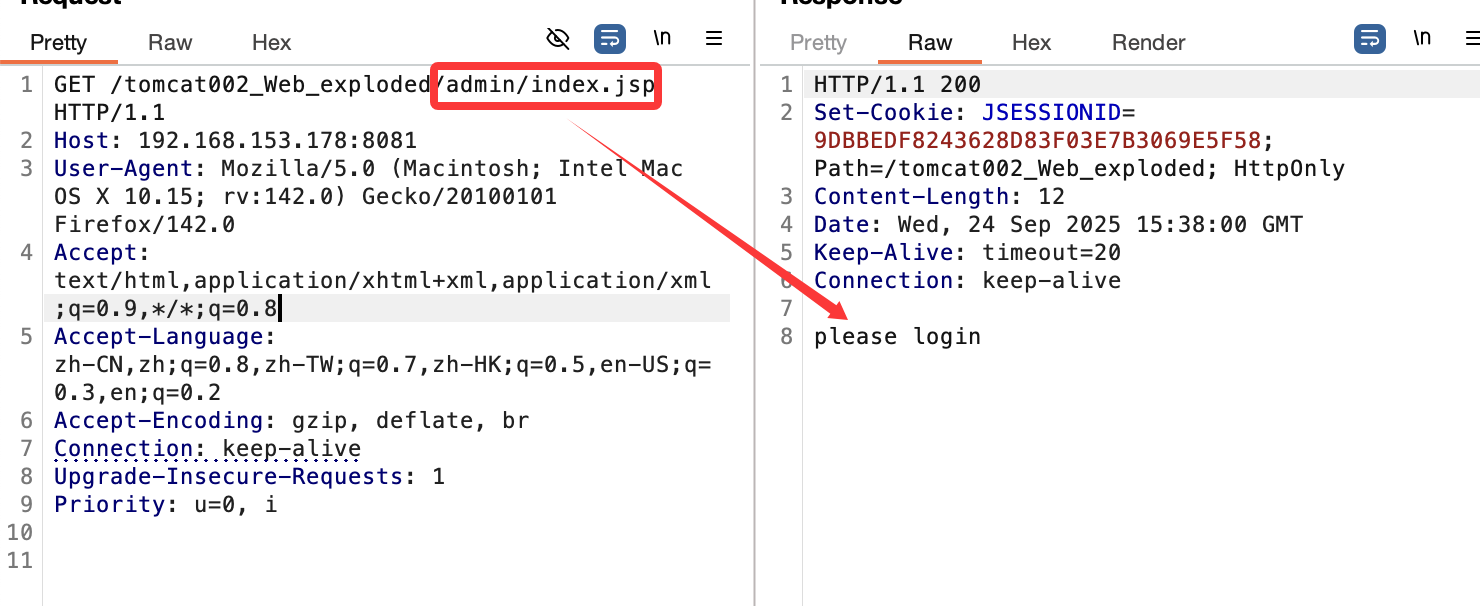
在这里设置了对admin目录的访问限制,也就是限制了index.jsp文件的访问,然后就是设置文件,目录结构为:
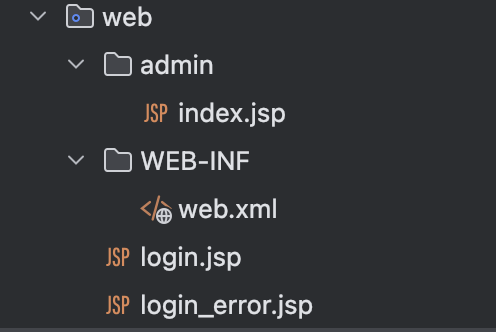
Login.jsp文件内容为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>登录</title>
</head>
<body>
<h2>管理员登录</h2>
<form method="post" action="j_security_check">
用户名: <input type="text" name="j_username" /><br/>
密码: <input type="password" name="j_password" /><br/>
<input type="submit" value="登录"/>
</form>
</body>
</html>
|
这里的j_security_check是tomcat内置的登陆校验机制,对应的账号密码就是前面的配置文件中设置的账号密码。
admin目录下的index.jsp内容为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<%--
Created by IntelliJ IDEA.
User: ASUS
Date: 2024/8/30
Time: 13:00
To change this template use File | Settings | File Templates.
--%>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>Title</title>
</head>
<body>
<h1>Hello admin</h1>
</body>
</html>
|
Login_error.jsp文件内容为:
1
2
3
4
5
6
7
8
9
10
|
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>登录失败</title>
</head>
<body>
<h2>用户名或密码错误!</h2>
<a href="login.jsp">返回重新登录</a>
</body>
</html>
|
然后开启tomcat即可,然后访问admin受限目录下的index.jsp,会跳转到login.jsp要求登陆:
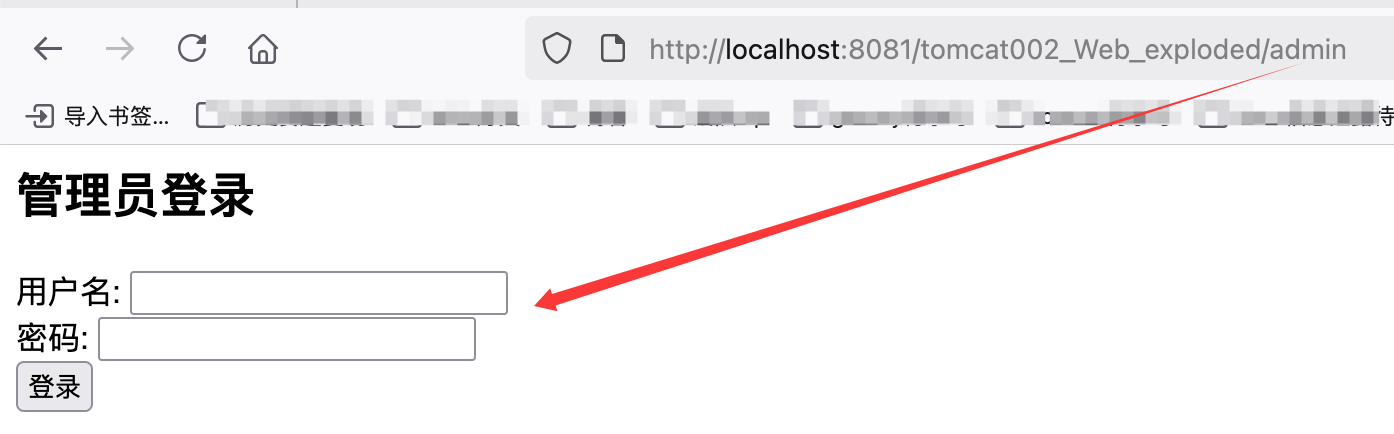
然后输入admin:123456就可以成功访问了:

tomcat设置cookie的情况如下:
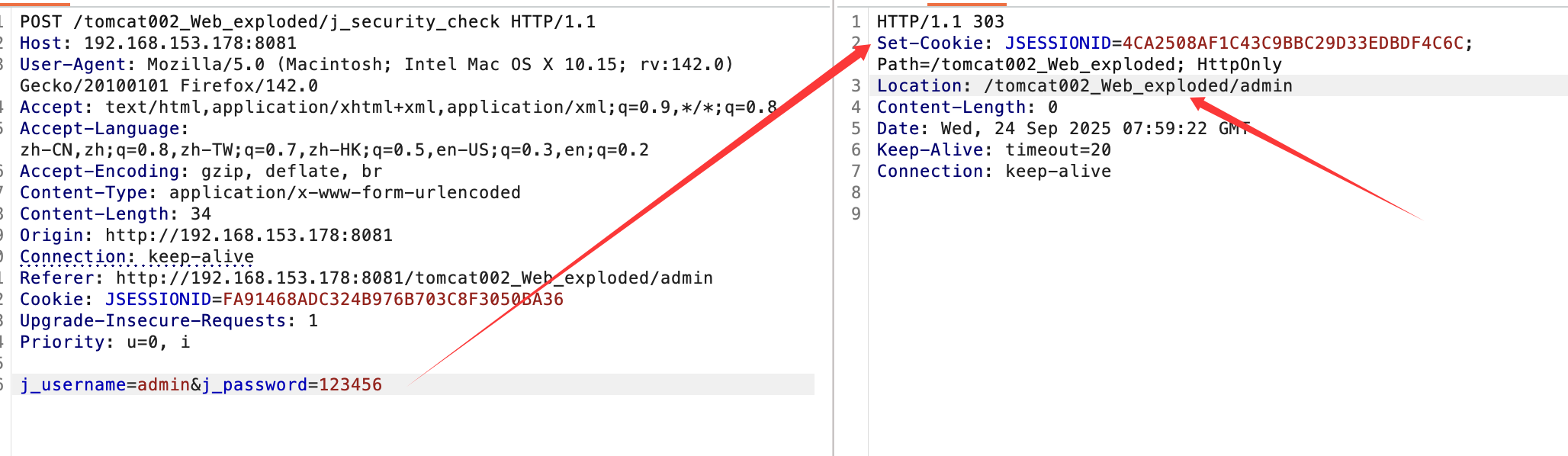
由此实现了一次简单的用户账号登陆的实现,并且实现了访问jsp资源时对身份的限制。当然也可以直接使用数据库来进行身份识别与限制,但主要是由java代码实现。
当然还可以限制ip等操作,但都是需要结合到xml配置文件来利用。
————————————
filter过滤器的利用
在tomcat架构中,我们就了解到了可以使用filter来过滤请求,只让符合条件的才能继续调用filterChain.doFilter(),否则就会被拦截。这就是一个天然可以被设计用来进行权限验证的过滤器(当然也可以做其他处理)。
在这里我们就可以仅使用java文件来进行一次登陆验证模拟。
在idea中指定的源根编辑java文件即可:
这里的目的还是访问到admin下的index.jsp文件,LoginServlet文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package org.example;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
@WebServlet("/login")
public class LoginServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String username = request.getParameter("username");
String password = request.getParameter("password");
if ("admin".equals(username) && "123".equals(password)) {
HttpSession session = request.getSession();
session.setAttribute("username", username);
response.sendRedirect(request.getContextPath() + "/admin/index.jsp");
} else {
response.sendRedirect(request.getContextPath() + "/login.jsp");
}
}
}
|
硬编码了一个账号密码,当然可以结合到数据库来使用。然后Testfilter.java文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package org.example;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
@WebFilter("/admin/*")
public class Testfilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Testfilter init");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse resp = (HttpServletResponse) servletResponse;
HttpSession session = request.getSession(false);
if (session == null) {
resp.sendRedirect(request.getContextPath()+"/login.jsp");
return;
}
String username = session.getAttribute("username").toString();
if("admin".equals(username)){
filterChain.doFilter(servletRequest, servletResponse);
}else{
resp.sendRedirect(request.getContextPath()+"/login.jsp");
}
}
@Override
public void destroy() {
}
}
|
可以看到对admin路由下的内容进行了限制,然后对cookie的获取进行了一些条件判断。修改login.jsp文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>登录</title>
</head>
<body>
<h2>管理员登录</h2>
<form method="post" action="login">
用户名: <input type="text" name="username" /><br/>
密码: <input type="password" name="password" /><br/>
<input type="submit" value="登录"/>
</form>
</body>
</html>
|
将post发送的action改为了后端处理的login路由。可以清空一下web.xml设置的配置,保留最基本的即可:
1
2
3
4
5
6
7
|
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
</web-app>
|
然后启动tomcat即可,访问admin/index.jsp,会直接跳转到登陆页面:
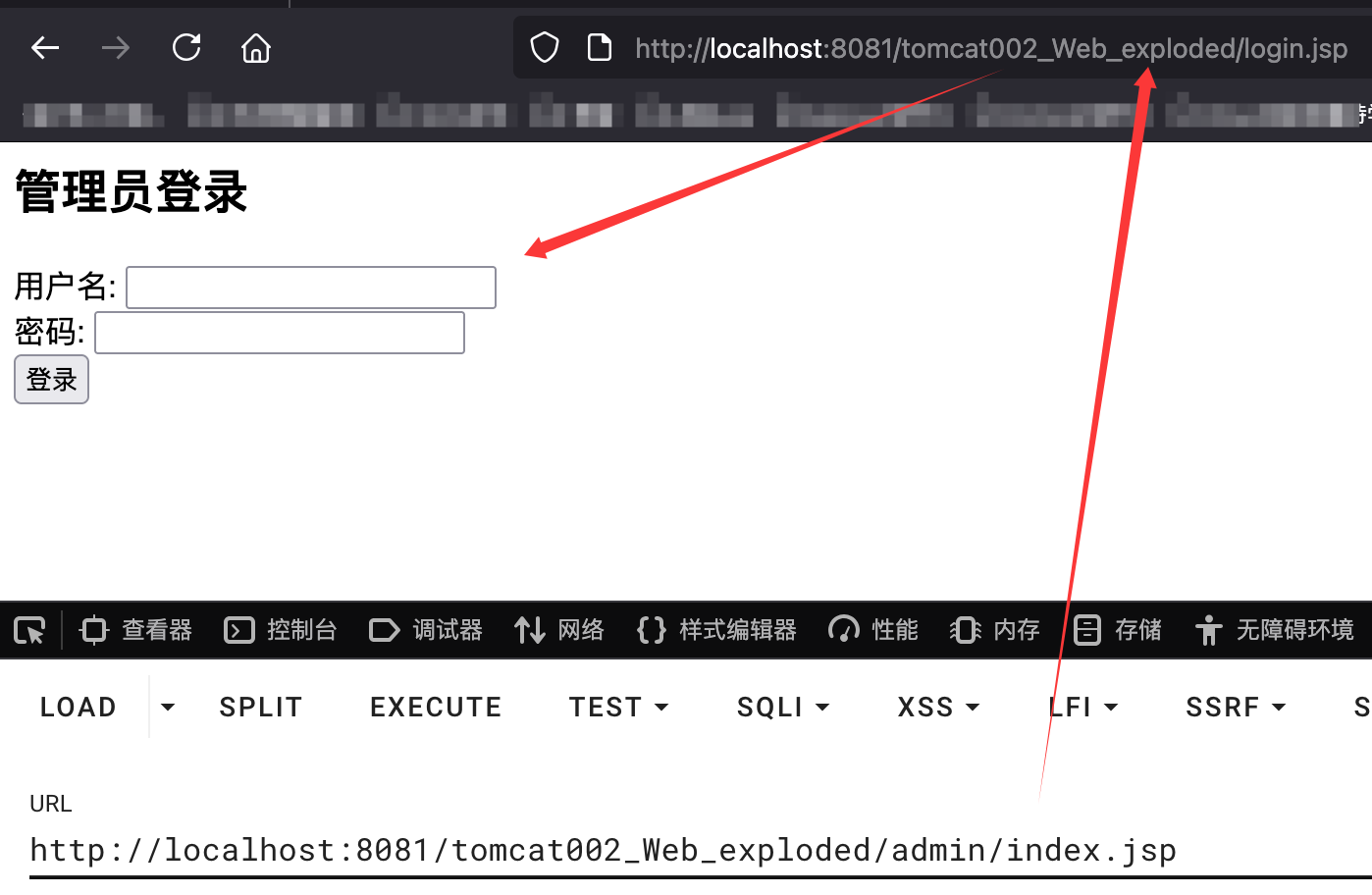
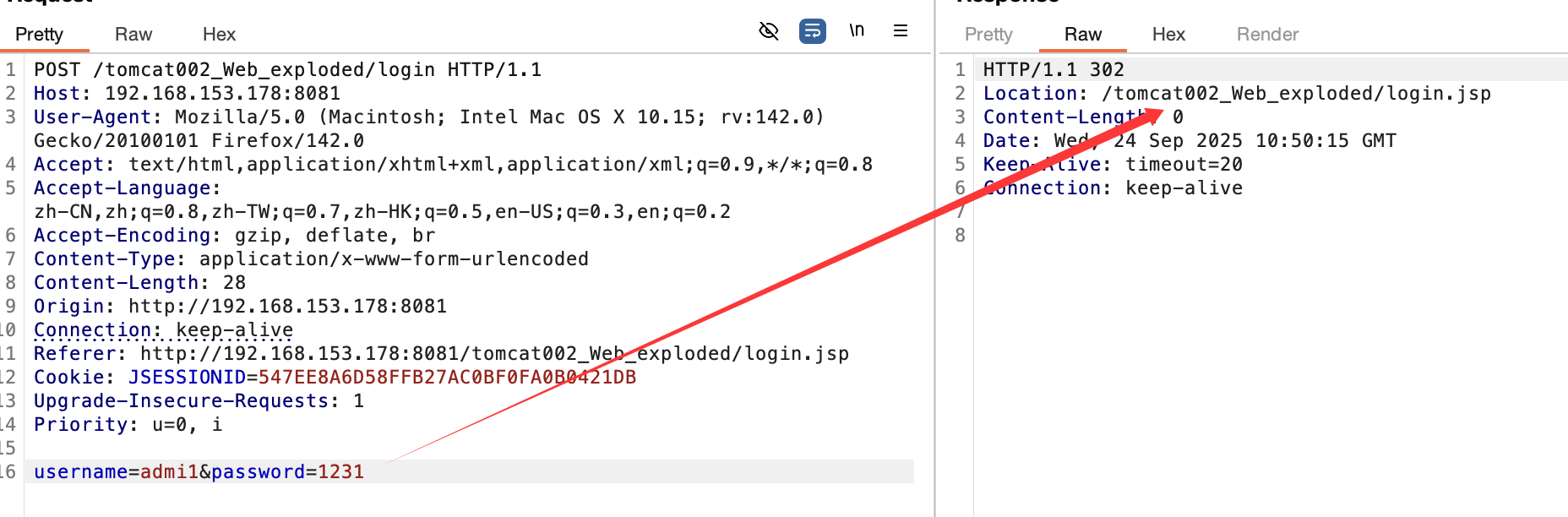
然后尝试登陆,错误账号密码:
正确账号密码:
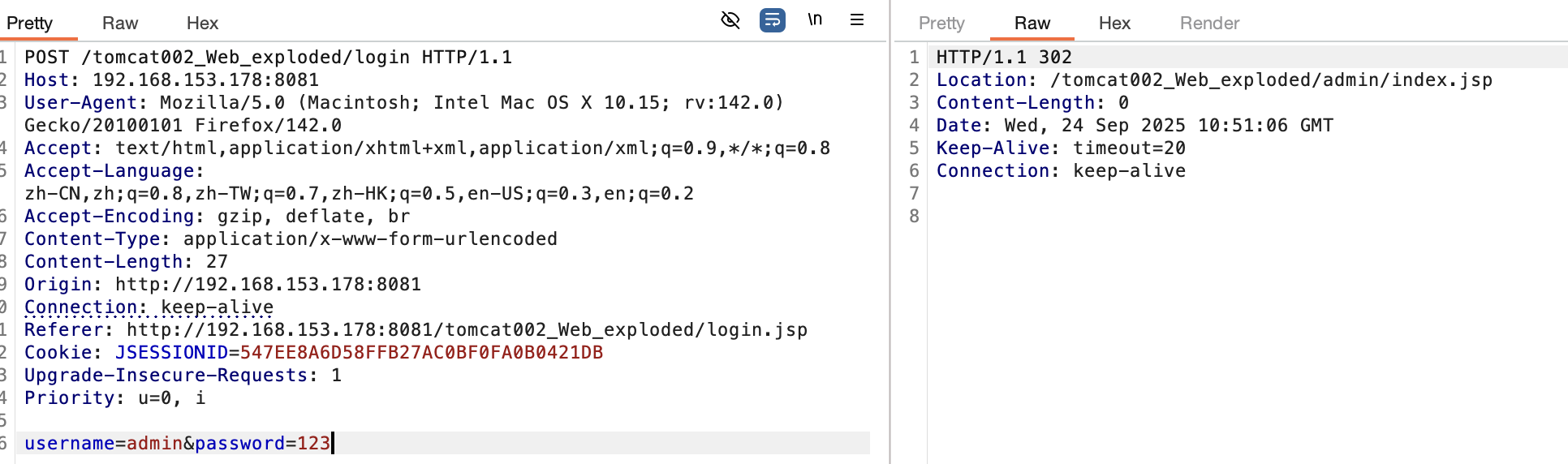
会跳转到指定的admin/index.jsp,在前端拿到cookie再访问:
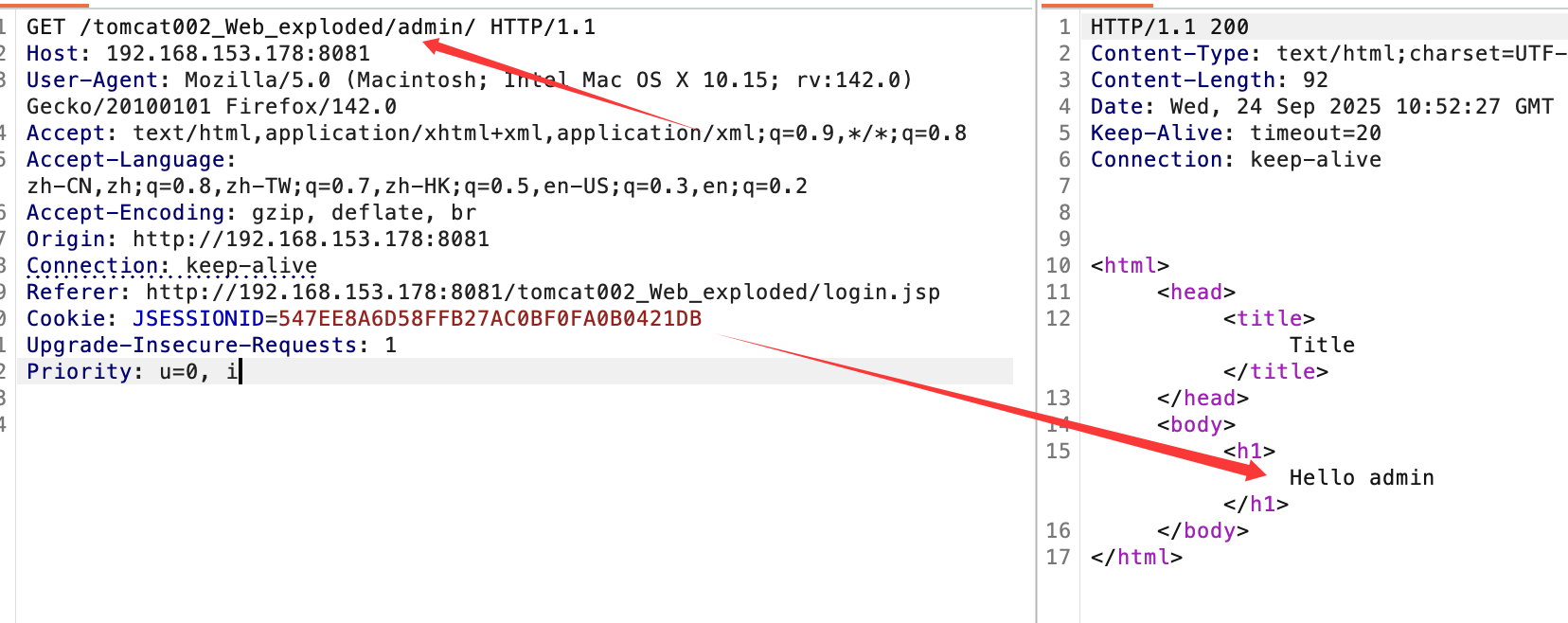
删去cookie:
两相对比,成功通过filter设置的权限验证。
以上实现了一个简单的java层面的利用filter过滤器来对路由设置身份验证,重点就在于这里使用的@WebFilter注解,想当于web.xml中的<filter> 和<filter-mapping>,故也是可以用web.xml来标注filter作用的路由的。
需要注意的一点就是使用@WebFilter注解无法对filter进行排序,而web.xml可以。
经典权限绕过分析
前文我们简单了解了一下两种权限设置的方法,当然还可能存在更多、更复杂的权限设置,这里来分析一下早已有所耳闻的分号等方式的绕过。
这里主要利用的是URL解析的差异性,当后端使用getRequestURI()或getRequestURL()函数来解析用户请求的URL时,若URl上包含有一些特殊符号,则可能造成访问限制绕过的风险。
在tomcat中,至少存在如下几个函数可以用来获取url上的请求路由:
- req.getRequestURL():返回全路径
- req.getRequestURI():返回除host的路径
- req.getContextPath():返回工程名部分的路径
- req.getServletPath():返回除去Host和工程名部分的路径
由于tomcat在解析请求路径时,会自行修正路径,然后再去访问servlet,故一般存在权限绕过漏洞,都是因为后端开发对路径的限制没有做好。
简单在doFilter()方法中添加如下代码来看回显是什么:
1
2
3
4
|
resp.getWriter().write("getRequestURL()的回显"+req.getRequestURL().toString()+"<br>");
resp.getWriter().write("getRequestURI()的回显"+req.getRequestURI()+"<br>");
resp.getWriter().write("getContextPath()的回显"+req.getContextPath()+"<br>");
resp.getWriter().write("getServletPath()的回显"+req.getServletPath()+"<br>");
|
从web端的回显来看,是如下内容:
1
2
3
4
|
getRequestURL()的回显http://localhost:8081/tomcat002_Web_exploded/admin/index.jsp
getRequestURI()的回显/tomcat002_Web_exploded/admin/index.jsp
getContextPath()的回显/tomcat002_Web_exploded
getServletPath()的回显/admin/index.jsp
|
非常符合函数本身的定义。
前面我们也说了,存在权限绕过的原因就是因为使用了getRequestURL()或者getRequestURI()来获取路径,然后再对目录进行判断。
简单写一个demo来对一些绕过点进行分析。
目录结构没有太大变化,文件内容改变如下:
LoginServlet.java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package org.example;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
public class LoginServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
HttpSession session = request.getSession();
String username = request.getParameter("username");
if (username == null) {
response.getWriter().write("You are not logged in");
return;
}
if ("admin".equals(username)) {
session.setAttribute("user", username);
response.sendRedirect(request.getContextPath() + "/admin/index.jsp");
} else {
response.getWriter().write("Invalid username");
}
}
}
|
Testfilter.java文件内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
package org.example;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebFilter("/admin/*")
public class Testfilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Testfilter init");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) servletRequest;
HttpServletResponse resp = (HttpServletResponse) servletResponse;
//漏洞点
String requestURL = req.getRequestURI();
if(requestURL.startsWith("/tomcat002_Web_exploded/admin/login")) {
//对登录页面设置白名单
filterChain.doFilter(servletRequest, servletResponse);
} else if(requestURL.endsWith(".jsp")) {
//对admin页面进行限制
Object user = req.getSession().getAttribute("user");
if(user == null || !user.toString().equals("admin")) {
resp.getWriter().write("please login");
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
}
@Override
public void destroy() {
}
}
|
然后改了一下WEB-INF/web.xml文件内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet-mapping>
<servlet-name>admin</servlet-name>
<url-pattern>/admin/login</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>admin</servlet-name>
<servlet-class>org.example.LoginServlet</servlet-class>
</servlet>
</web-app>
|
整个代码实现的功能就是对/admin路由下的资源设置了filter过滤器,然后用过配置web.xml文件从而使url上访问admin/login会转交给本地实现的servlet进行逻辑实现(这样就可以让login在filter过滤下,正常实现filter的过滤功能),然后设置的获取admin/index.jsp文件需要session为admin。
注意这里强制设置了如果想正常访问.jsp文件,必须包含有这个后缀,否则是回显为空的。
在自定义的filter中,从逻辑看似乎是无懈可击,但其实存在非常严重的权限绕过漏洞,关键就是tomcat会自行修正路径,这与tomcat的源码实现相关。现在先来看正常的逻辑:
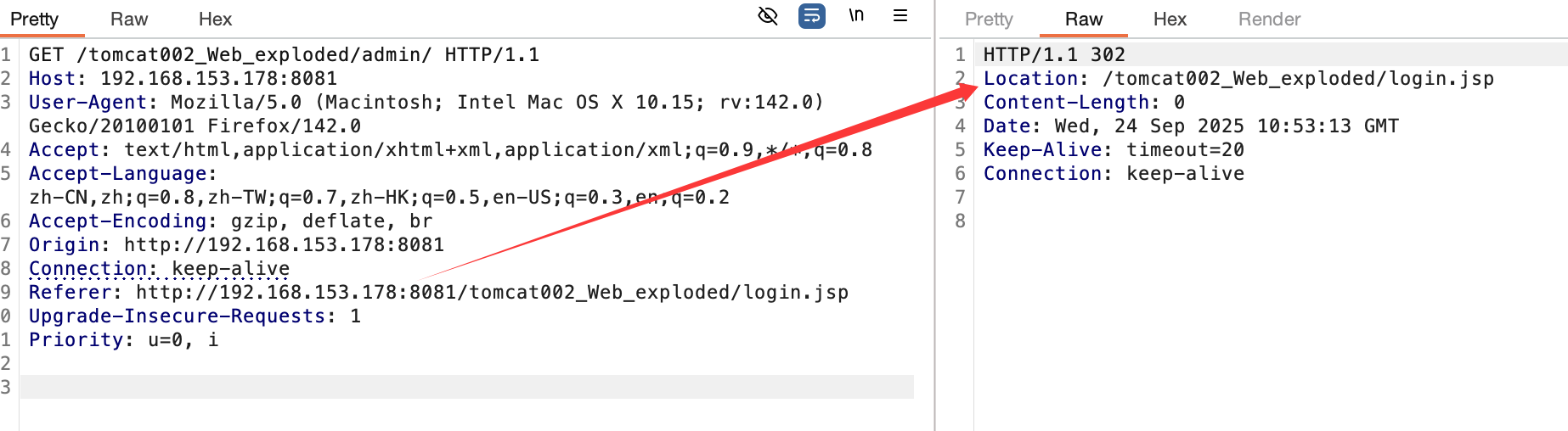
直接访问admin界面:
在filter过滤器就被拦住。尝试登陆:
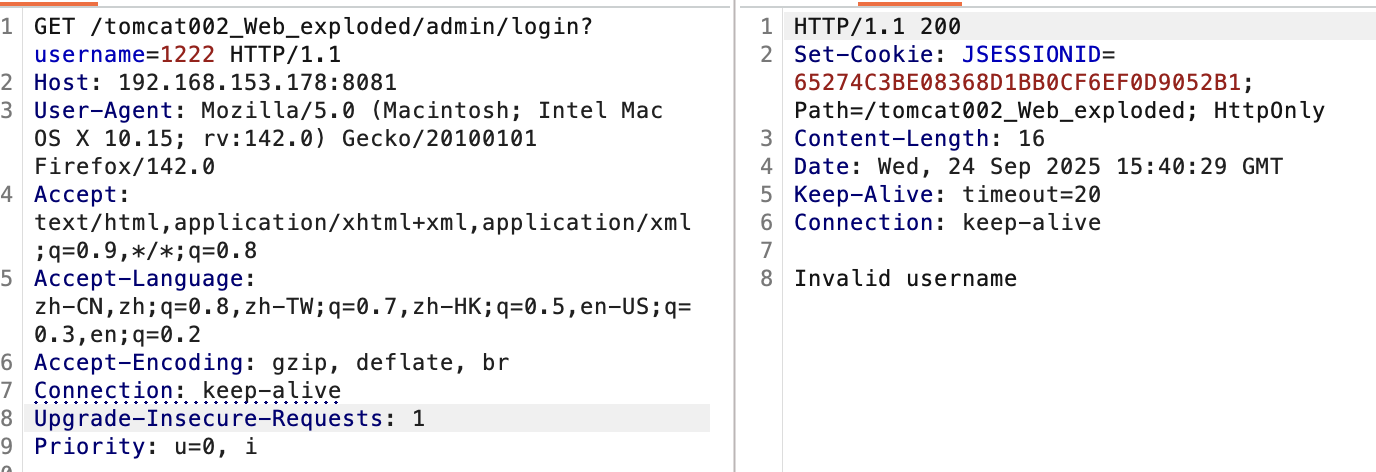
在servlet的doGet()方法做出的判断。正常登陆后:
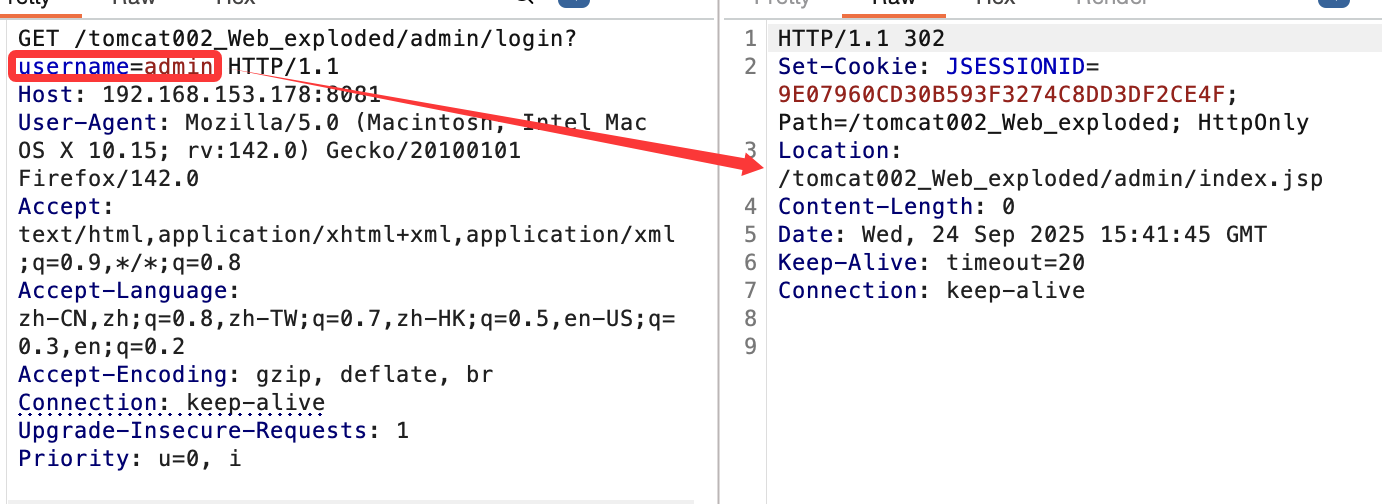
获取到了session然后会跳转。拿到cookie后就可以访问了:
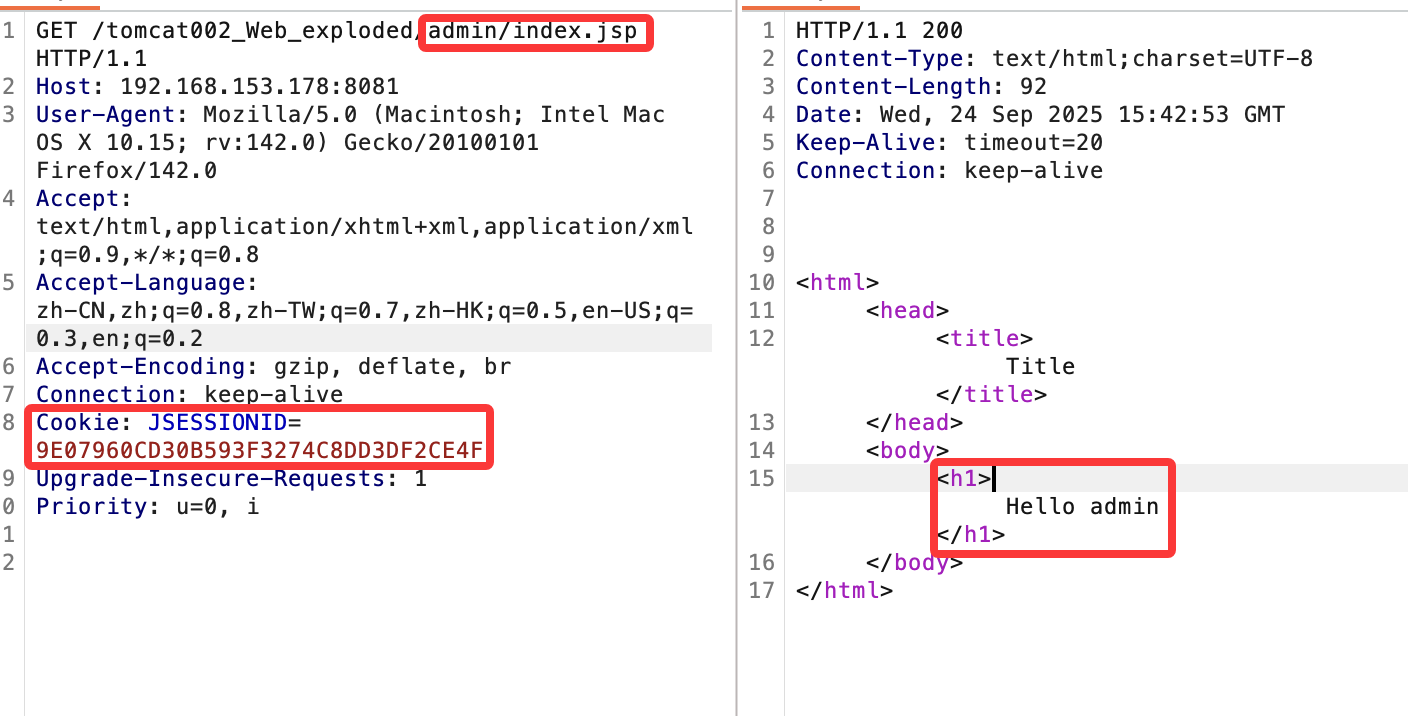
由此成功实现鉴权,可以访问到对应的admin的内容。
从上述过程中,在代码层面可以说这个鉴权方式没有任何问题,但是结合到tomcat就不一样了,下面来了解一些绕过方式。
../绕过
直接来看绕过方式,如下图使用两个../:
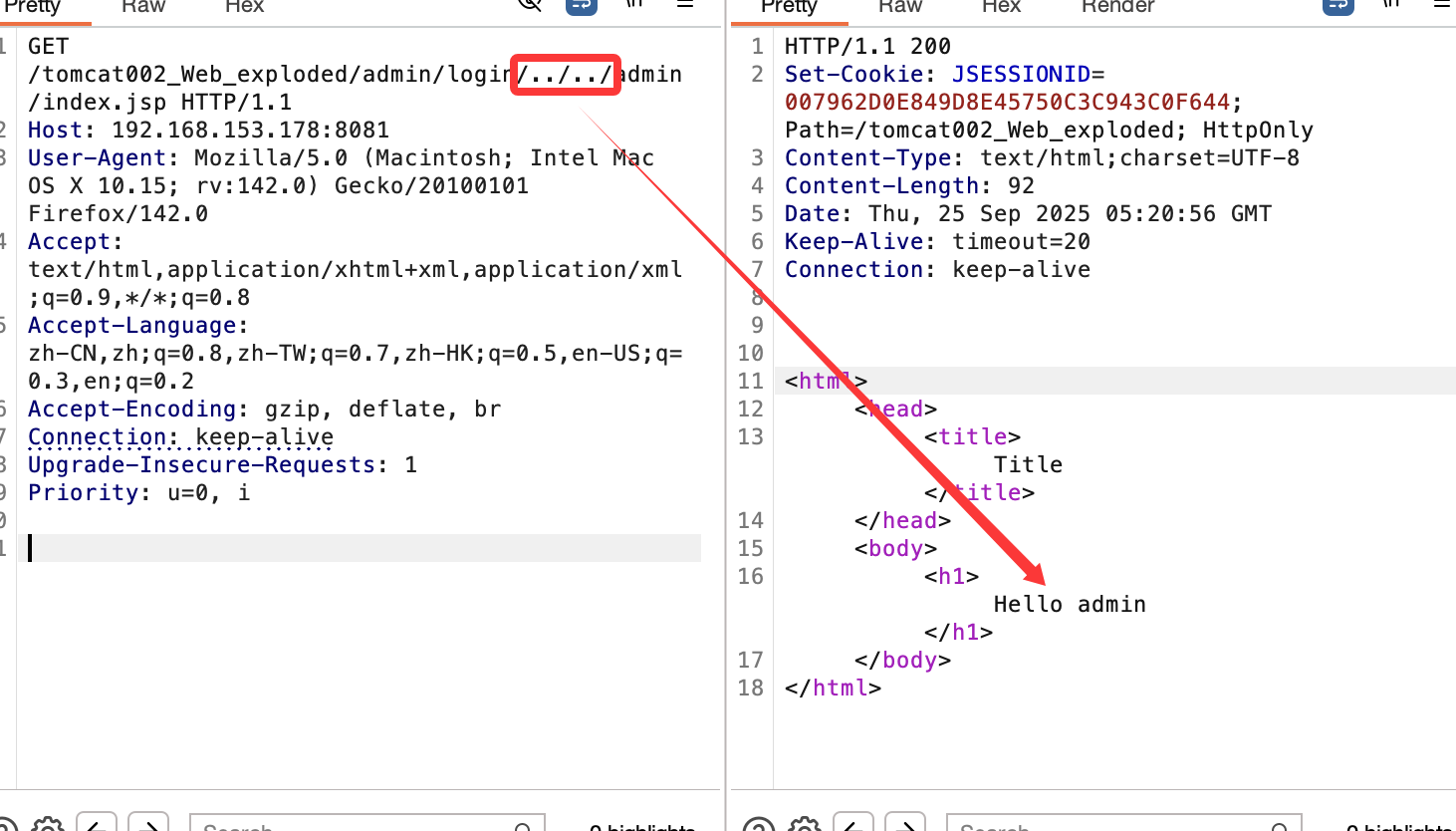
一个../也可以:
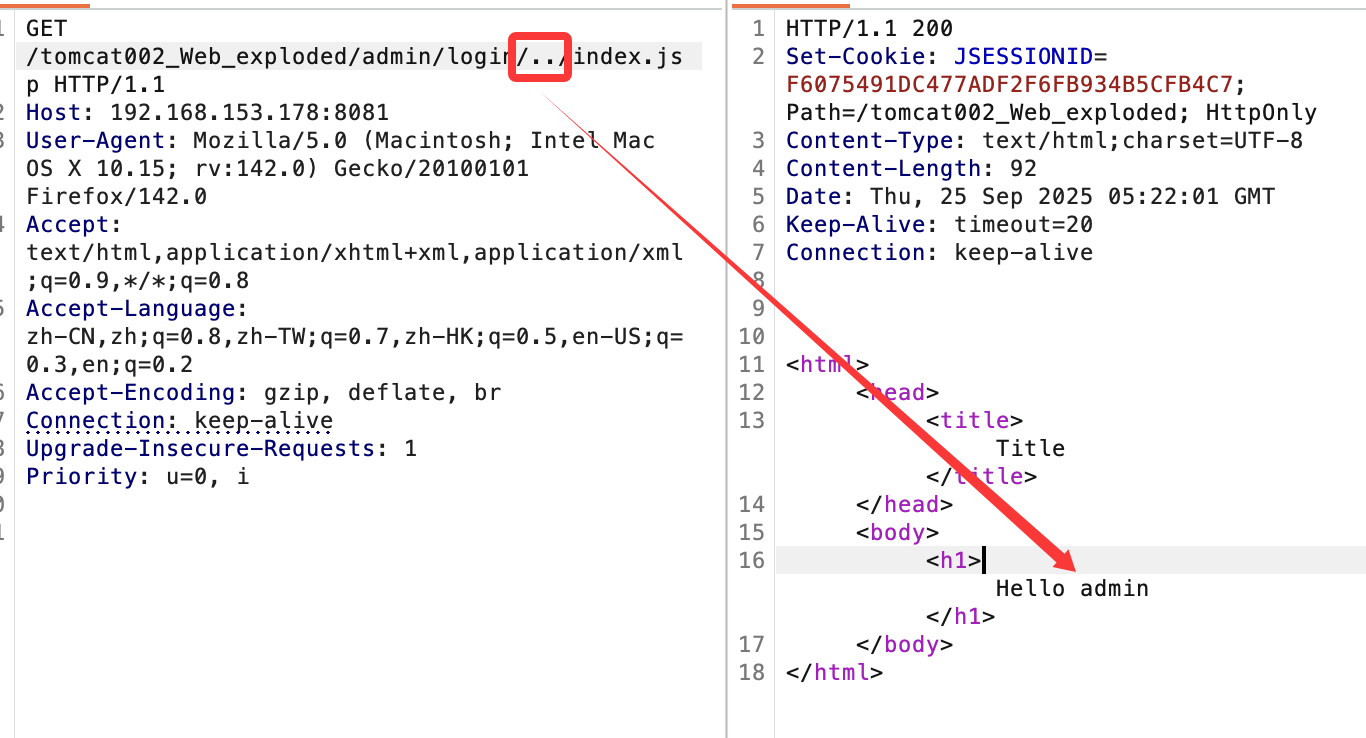
简单从现象来看,似乎非常像我们经常遇到的目录穿越漏洞,从代码设置的filter来看:
成功进入第一个admin/login,就正常调用filterChain.doFilter(),但是经过tomcat的路径修正,故其本质会调用到.jsp指定的servlet容器,从而实现了权限绕过。
tomcat对路径修正的代码存在于CoyoteAdapter类的postParseRequest()方法:
这里调用了req.requestURI()获取uri,继续往后走,到调用convert()方法:
这里的convert是一个url解码的操作,我们后续再详细谈。继续往后看,会调用normalize()方法:
可以看出参数传递的还是获取到的uri,跟进normalize()方法:
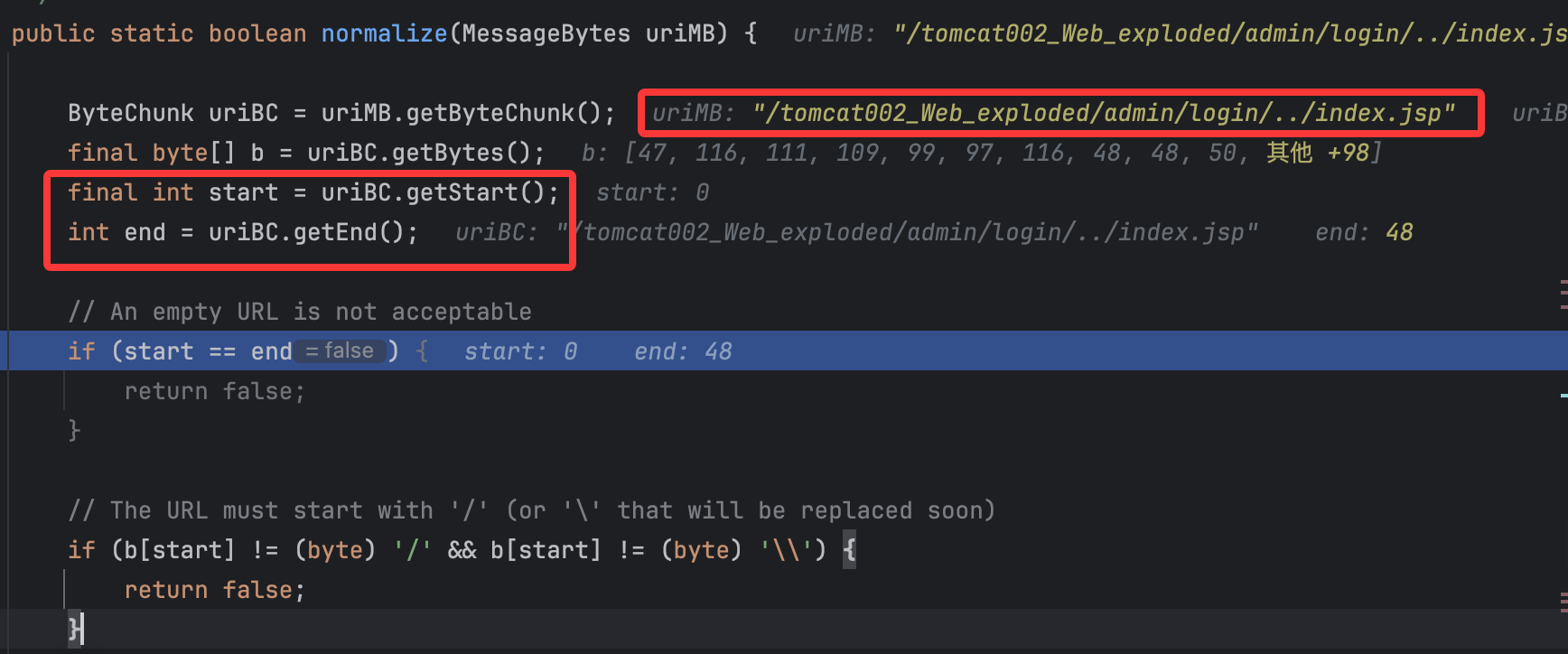
获取具体的uri,然后获取其起始以及最后的位置(就是获取其长度),后续比较关键的就是如下代码:

这里的逻辑就是循环清理/./,直到在uriBC中找不到/./,过程就是/a/./b替换为/a/b,故长度需要-2。
后续的比较关键的代码就是如下:
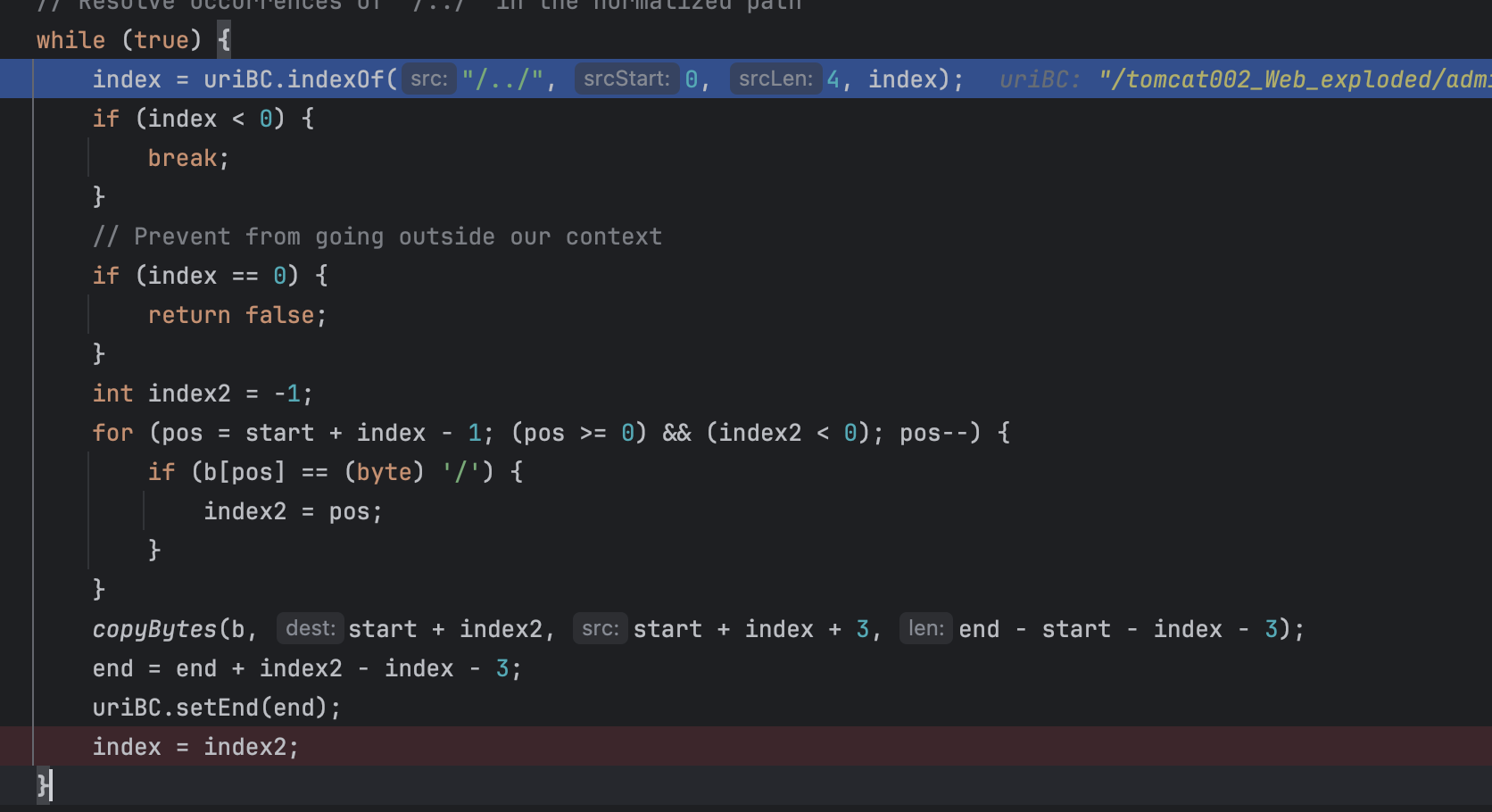
这里继续清理/../,也是这一部分的../绕过的原理所在,从代码逻辑看来,这就是一个用来实现另一类的“目录穿越”的路径清理,代码逻辑就是:
- 如果匹配到
/../在开头,那么就会跳到context根目录之外,就直接返回false。
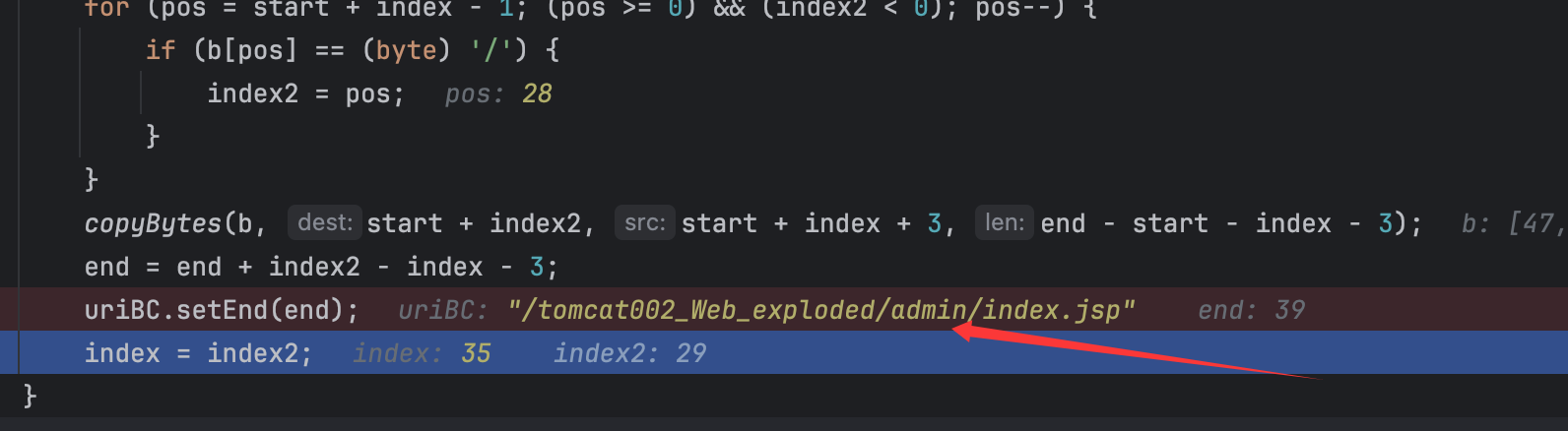
- 如果匹配到后续位置,比如
admin/login/../index.jsp,那么就会寻找/../前的一个/,然后将前一个目录名+/../一起删掉,在这里体现出来就是把login/../一起删掉,从而变成了admin/index.jsp,如下图:
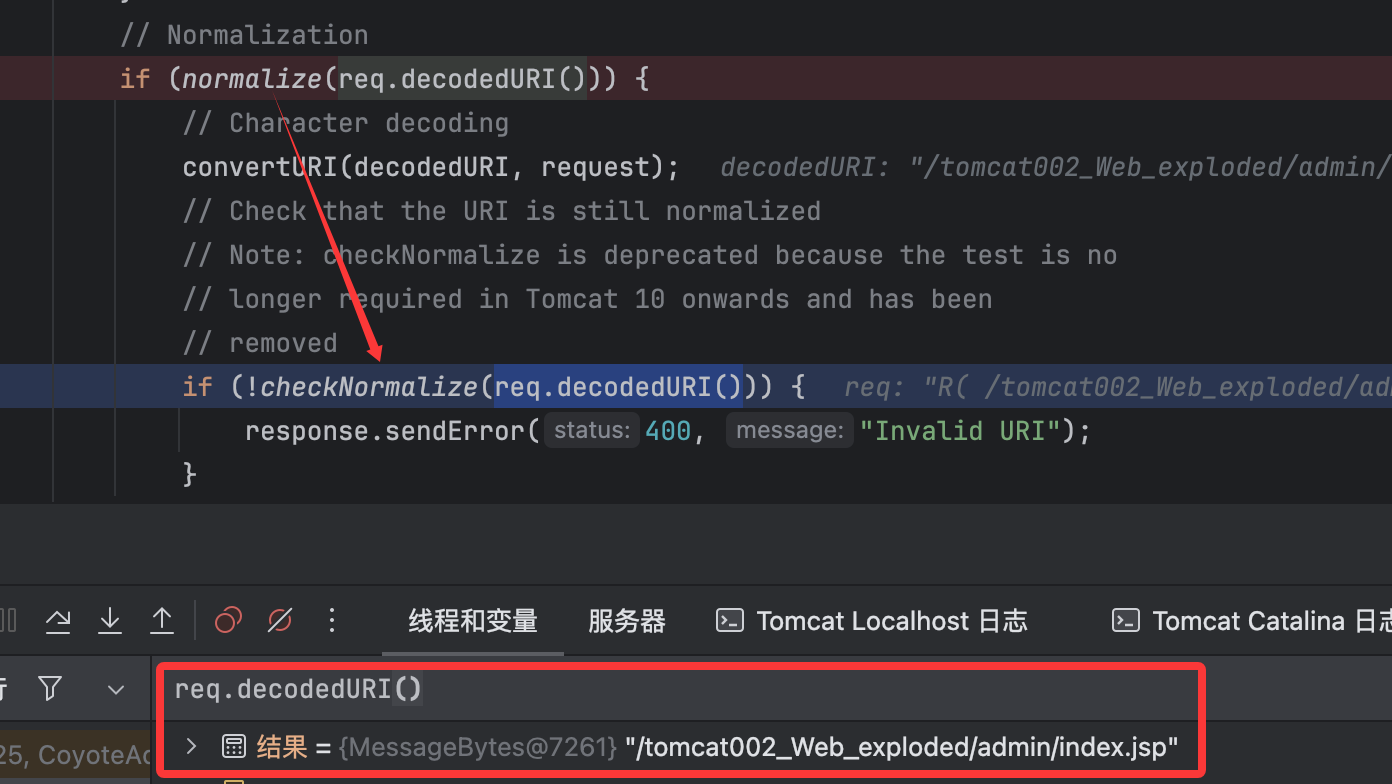
这样后续指定的url就变成了admin/index.jsp。当调用完了normalize()方法,还会调用checkNormalize()再次检查,但是这次是匹配到存在/./或者/../是直接返回400:
————————
此时的调用栈:
1
2
3
4
5
6
7
8
9
10
11
|
postParseRequest:688, CoyoteAdapter (org.apache.catalina.connector)
service:341, CoyoteAdapter (org.apache.catalina.connector)
service:397, Http11Processor (org.apache.coyote.http11)
process:63, AbstractProcessorLight (org.apache.coyote)
process:935, AbstractProtocol$ConnectionHandler (org.apache.coyote)
doRun:1792, NioEndpoint$SocketProcessor (org.apache.tomcat.util.net)
run:52, SocketProcessorBase (org.apache.tomcat.util.net)
runWorker:1189, ThreadPoolExecutor (org.apache.tomcat.util.threads)
run:658, ThreadPoolExecutor$Worker (org.apache.tomcat.util.threads)
run:63, TaskThread$WrappingRunnable (org.apache.tomcat.util.threads)
run:745, Thread (java.lang)
|
再看我们调用到filter的调用栈:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
doFilter:26, Testfilter (org.example)
internalDoFilter:168, ApplicationFilterChain (org.apache.catalina.core)
doFilter:144, ApplicationFilterChain (org.apache.catalina.core)
invoke:168, StandardWrapperValve (org.apache.catalina.core)
invoke:90, StandardContextValve (org.apache.catalina.core)
invoke:482, AuthenticatorBase (org.apache.catalina.authenticator)
invoke:130, StandardHostValve (org.apache.catalina.core)
invoke:93, ErrorReportValve (org.apache.catalina.valves)
invoke:656, AbstractAccessLogValve (org.apache.catalina.valves)
invoke:74, StandardEngineValve (org.apache.catalina.core)
service:346, CoyoteAdapter (org.apache.catalina.connector)
service:397, Http11Processor (org.apache.coyote.http11)
process:63, AbstractProcessorLight (org.apache.coyote)
process:935, AbstractProtocol$ConnectionHandler (org.apache.coyote)
doRun:1792, NioEndpoint$SocketProcessor (org.apache.tomcat.util.net)
run:52, SocketProcessorBase (org.apache.tomcat.util.net)
runWorker:1189, ThreadPoolExecutor (org.apache.tomcat.util.threads)
run:658, ThreadPoolExecutor$Worker (org.apache.tomcat.util.threads)
run:63, TaskThread$WrappingRunnable (org.apache.tomcat.util.threads)
run:745, Thread (java.lang)
|
两相对比就可以知道这个绕过的原理了。
由于tomcat的路径修正,让我们请求的/tomcat002_Web_exploded/admin/login/../index.jsp变成了/tomcat002_Web_exploded/admin/index.jsp,直接指向了需要鉴权的页面,但是在后续的调用中,到我们设置的filter时:
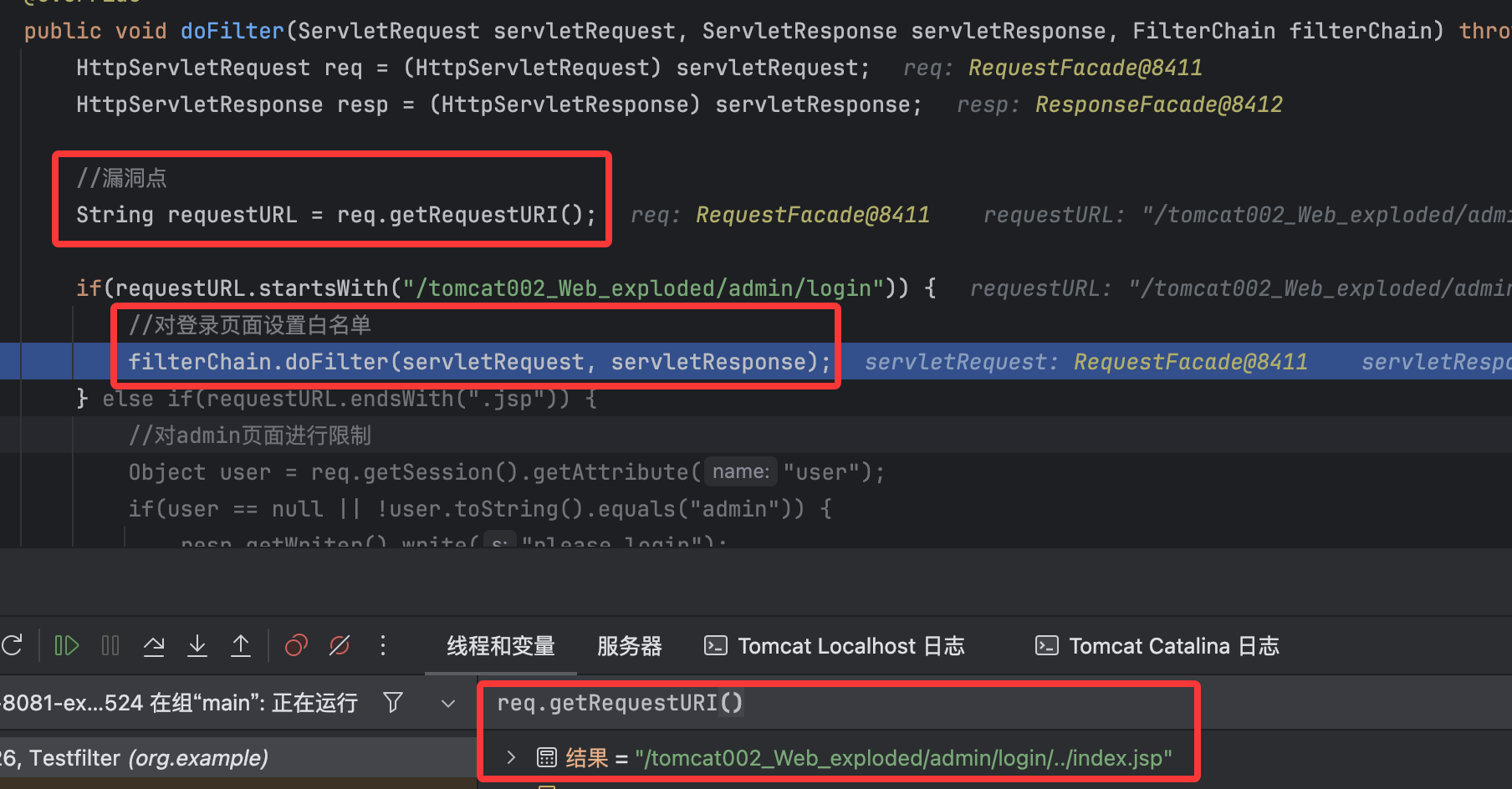
还是使用的getRequestURI()来获取全ip,导致进入了白名单,放行了当前的url请求,但是经过路径修正,实际指向的是admin/index.jsp,故成功绕过鉴权拿到admin页面的信息。
;绕过
前面忘记分析了一个点,先给出对前面绕过方式进行限制的代码,来看看是否还可以绕过,修改Testfilter.java文件代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
package org.example;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebFilter("/admin/*")
public class Testfilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Testfilter init");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) servletRequest;
HttpServletResponse resp = (HttpServletResponse) servletResponse;
//漏洞点
String requestURL = req.getRequestURI();
int waf=0;
waf = requestURL.indexOf("../");
if(waf>0){
resp.getWriter().write("url error ,do not attack");
return;
}
if(requestURL.startsWith("/tomcat002_Web_exploded/admin/login")) {
//对登录页面设置白名单
filterChain.doFilter(servletRequest, servletResponse);
} else if(requestURL.endsWith(".jsp")) {
//对admin页面进行限制
Object user = req.getSession().getAttribute("user");
if(user == null || !user.toString().equals("admin")) {
resp.getWriter().write("please login");
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
}
@Override
public void destroy() {
}
}
|
加了一个对../的限制:
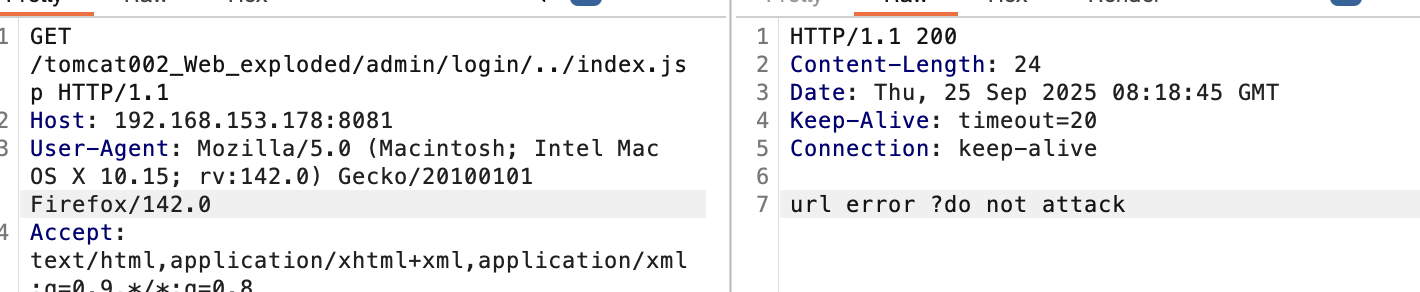
如何绕过,如下图:
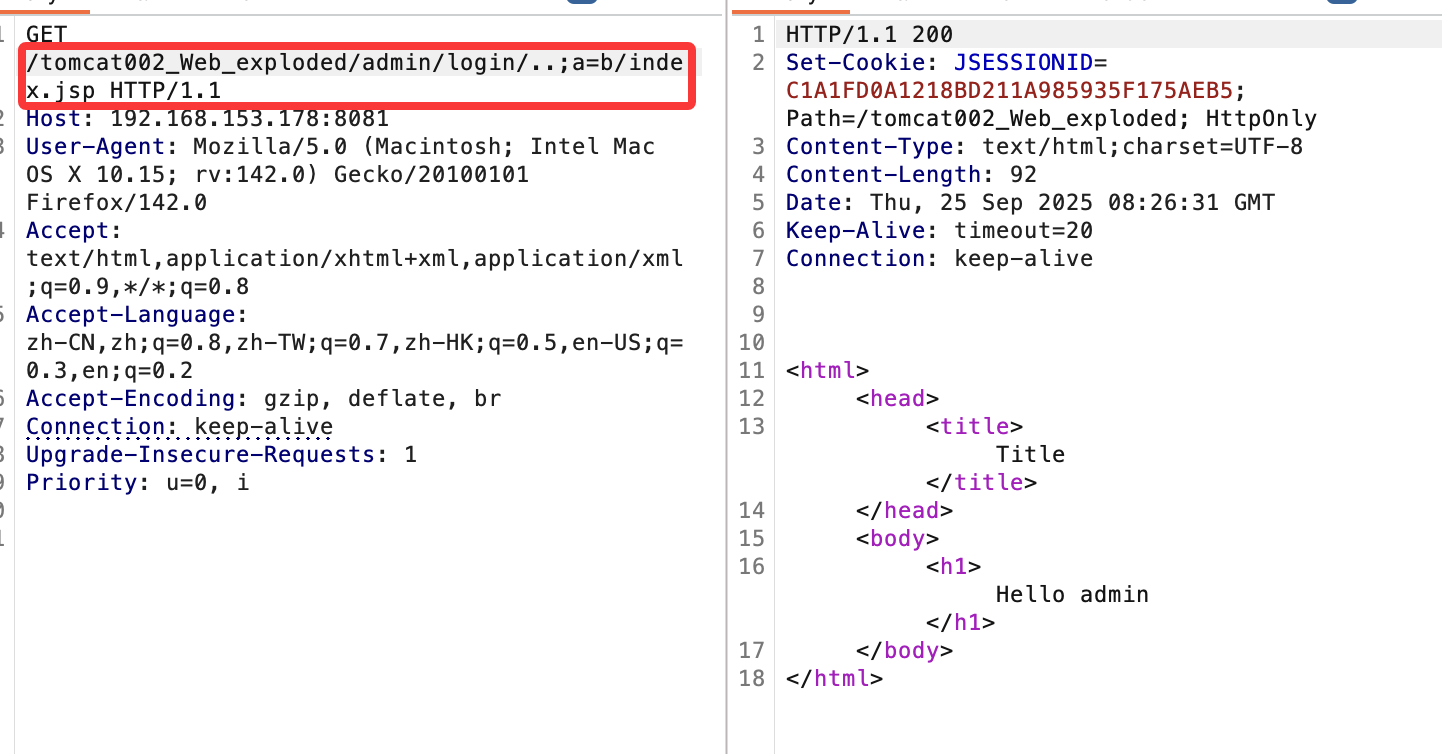
是的,使用的分号。那么这里为什么呢。打断点调试如下:
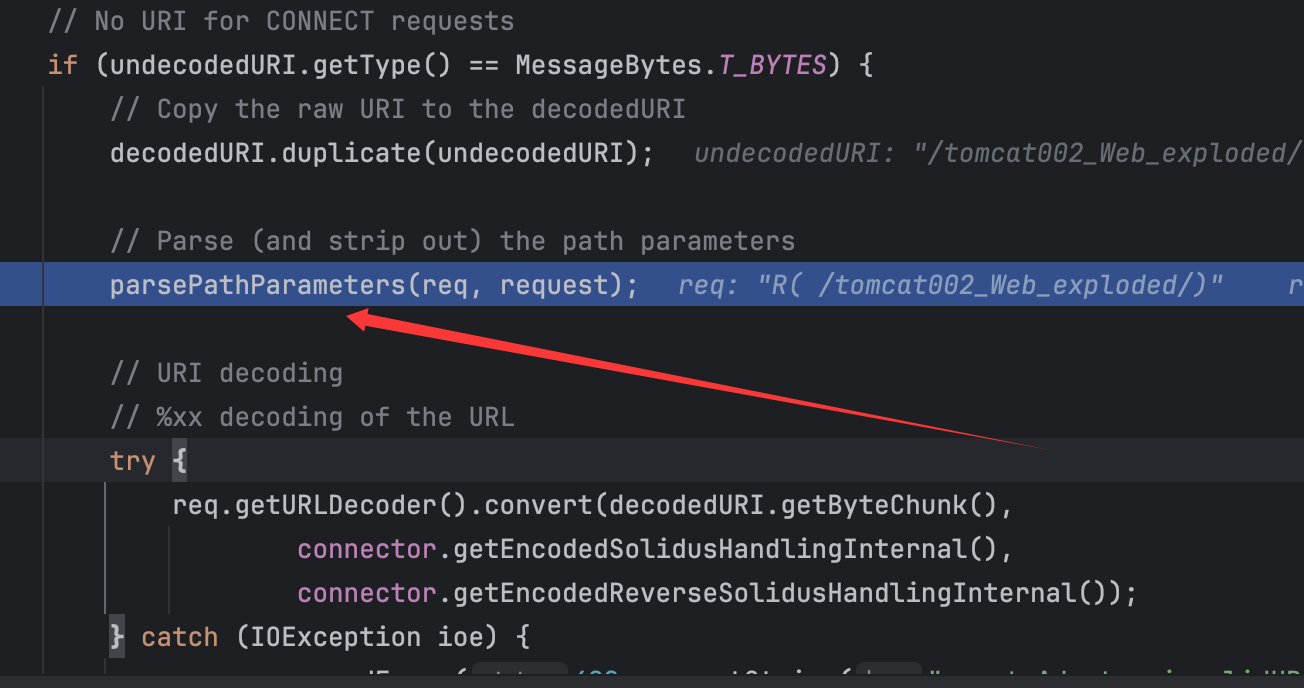
进入这里调用的parsePathParameters()方法,如图可看出后续进行了url解码,也就是前面分析的。跟进parsePathParameters()方法:
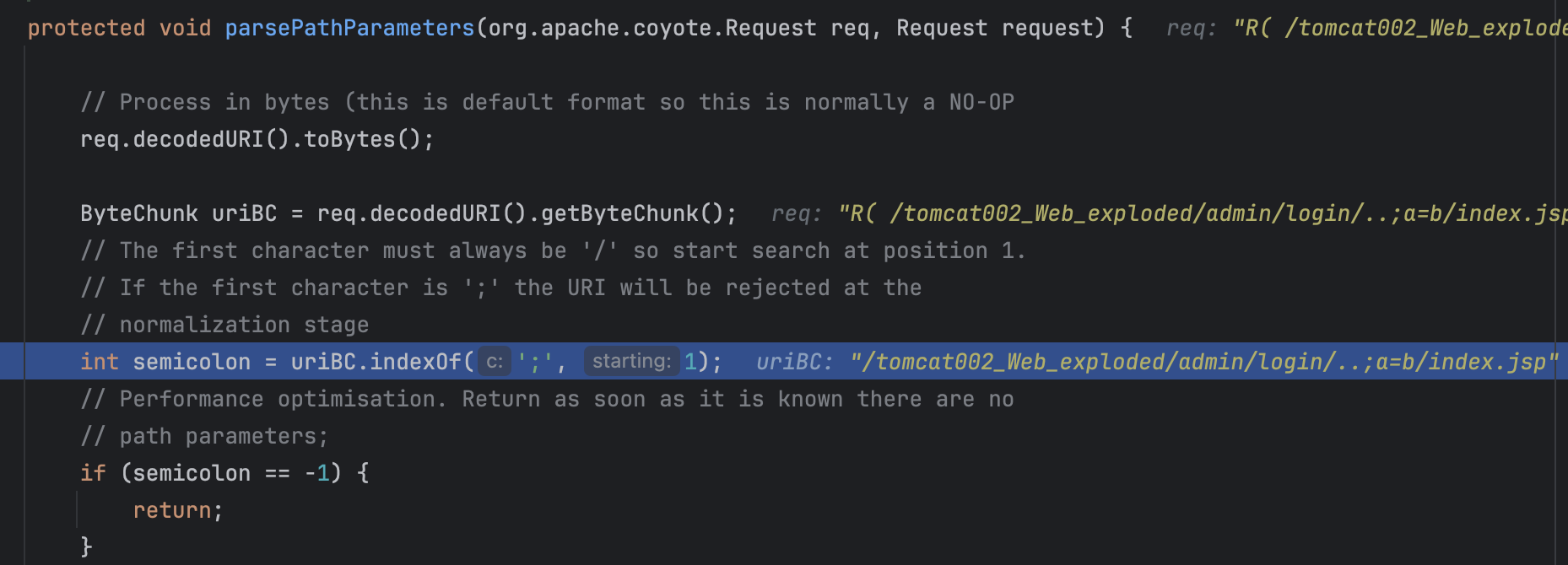
需要有分号,然后寻找其中的参数:
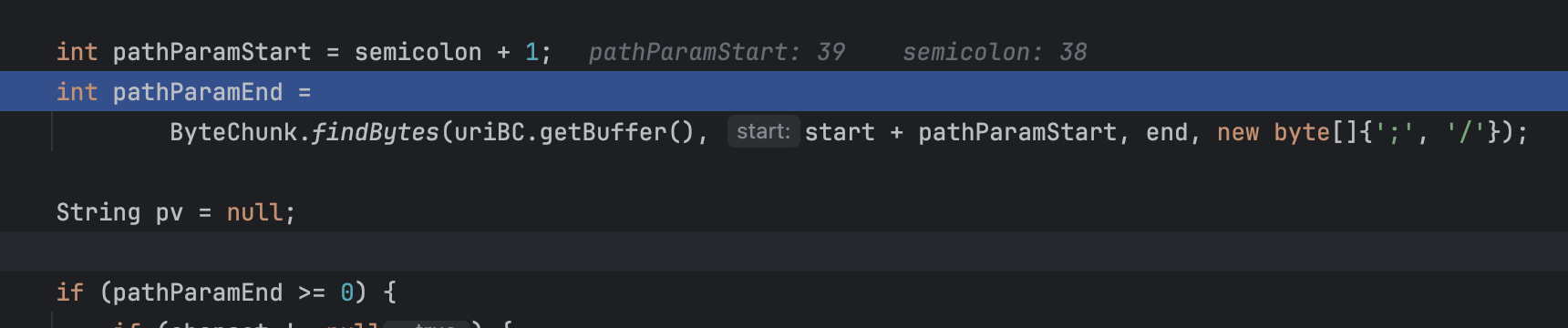
这里匹配逻辑就是从第一个分号到下一个分号,或者到下一个/,比如;a=b;c=d/,那么就会匹配到a=b和c=d两个键值对(也是循环进行匹配的,每次只取一个键值对),当匹配到后,会将;a=b一起删掉,故最后剩下的uri为:
1
|
tomcat002_Web_exploded/admin/login/../index.jsp
|
由此就是又可以达到一次权限绕过。
那么为什么会存在这种逻辑呢,主要还是为了在获取到参数后对request对象进行”填充“,为对象添加一些必要的属性:
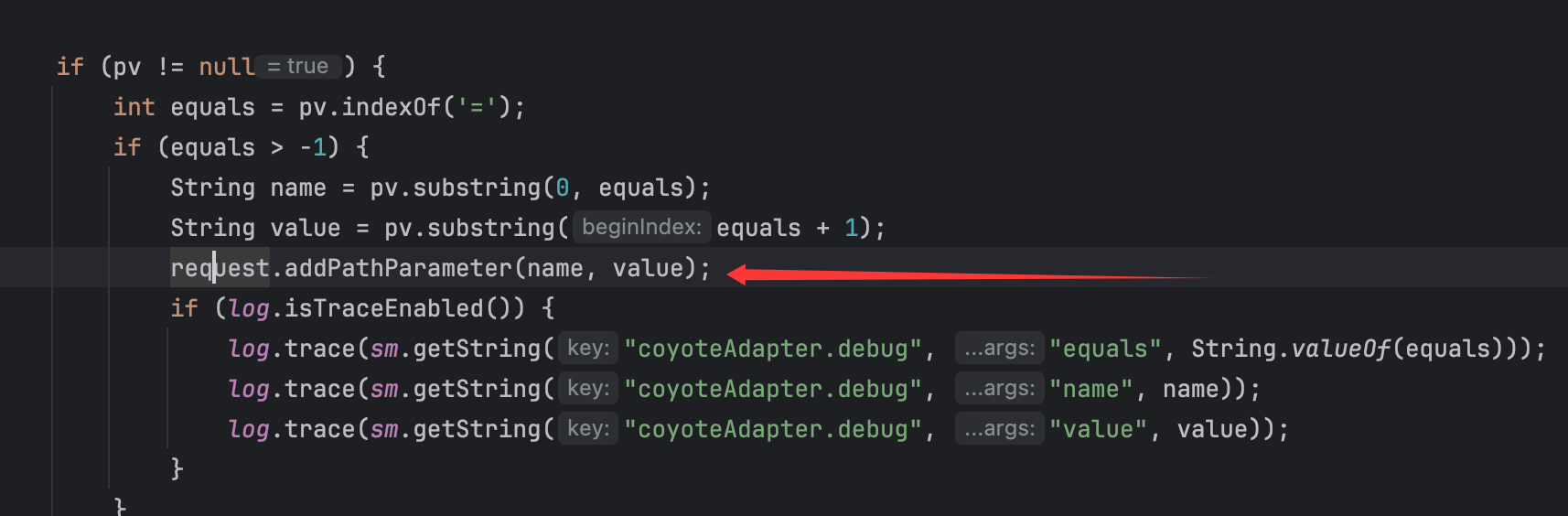
过程很好理解,在filter中通过getRequestURI()获取完整目录,然后会进入到登陆口白名单,再然后会访问经过路径修正的servlet,从而成功实现权限绕过。
——————————————
由此可以知道整体的逻辑就是 先url解码=>去除分号及其匹配的键值对 => 去掉./ =》去掉../以及前一个目录。
url编码绕过
那么我将代码改成如下还是否能绕过呢:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
package org.example;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebFilter("/admin/*")
public class Testfilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Testfilter init");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) servletRequest;
HttpServletResponse resp = (HttpServletResponse) servletResponse;
//漏洞点
String requestURL = req.getRequestURI();
int waf=0;
waf = requestURL.indexOf("..");
if(waf>0){
resp.getWriter().write("url error ,do not attack");
return;
}
if(requestURL.startsWith("/tomcat002_Web_exploded/admin/login")) {
//对登录页面设置白名单
filterChain.doFilter(servletRequest, servletResponse);
} else if(requestURL.endsWith(".jsp")) {
//对admin页面进行限制
Object user = req.getSession().getAttribute("user");
if(user == null || !user.toString().equals("admin")) {
resp.getWriter().write("please login");
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
}
@Override
public void destroy() {
}
}
|
直接釜底抽薪,过滤掉关键的..符号(本来想设置过滤.,后面发现文件名有一个.):

无法利用,如下绕过方式:
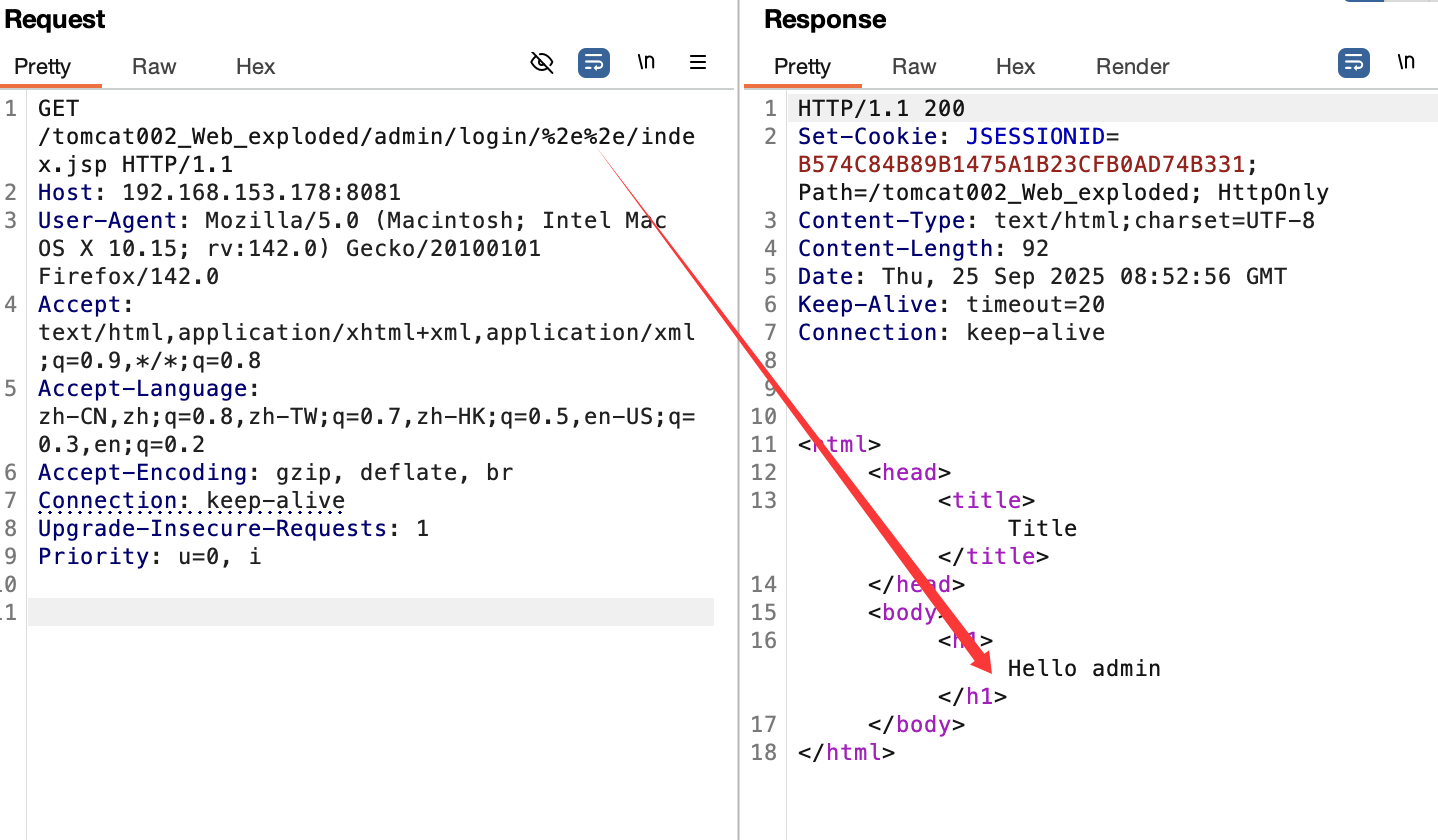
成功实现权限绕过。前面就提到了tomcat修正路径时会url解码,直接跟进对应的convert()函数,这就是一个url解码的函数,其中有两个需要注意的点:
循环解码:
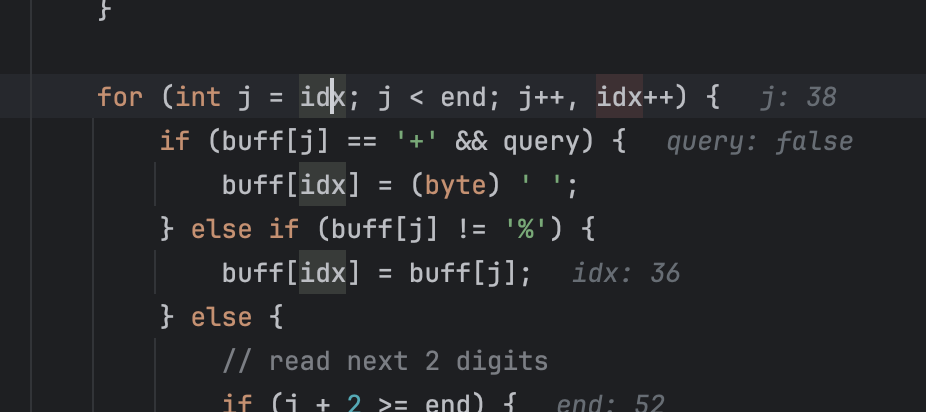
其次是对解码出来的内容有匹配:
如图所示有/和\,还有%,这里关注/,可以将url上的/编码,会是如下情况::
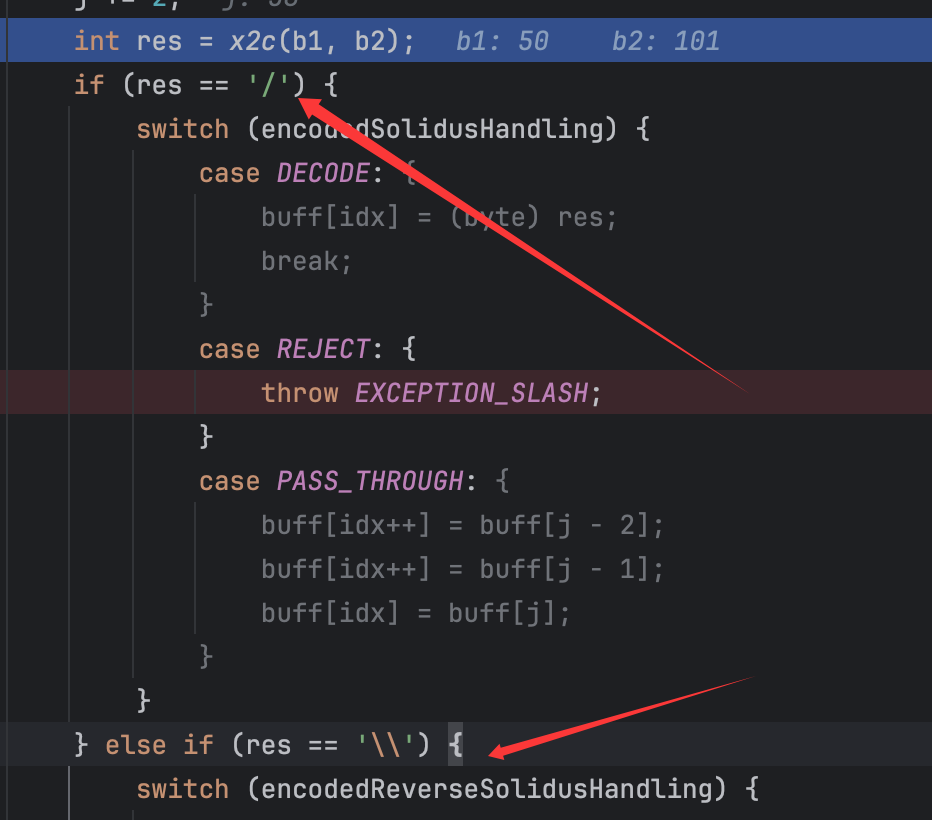
关键在于这里的encodedSolidusHandling,三个模式分别对应如下说明:
DECODE:解码成/。REJECT:拒绝请求,抛出异常。PASS_THROUGH:保持原样。
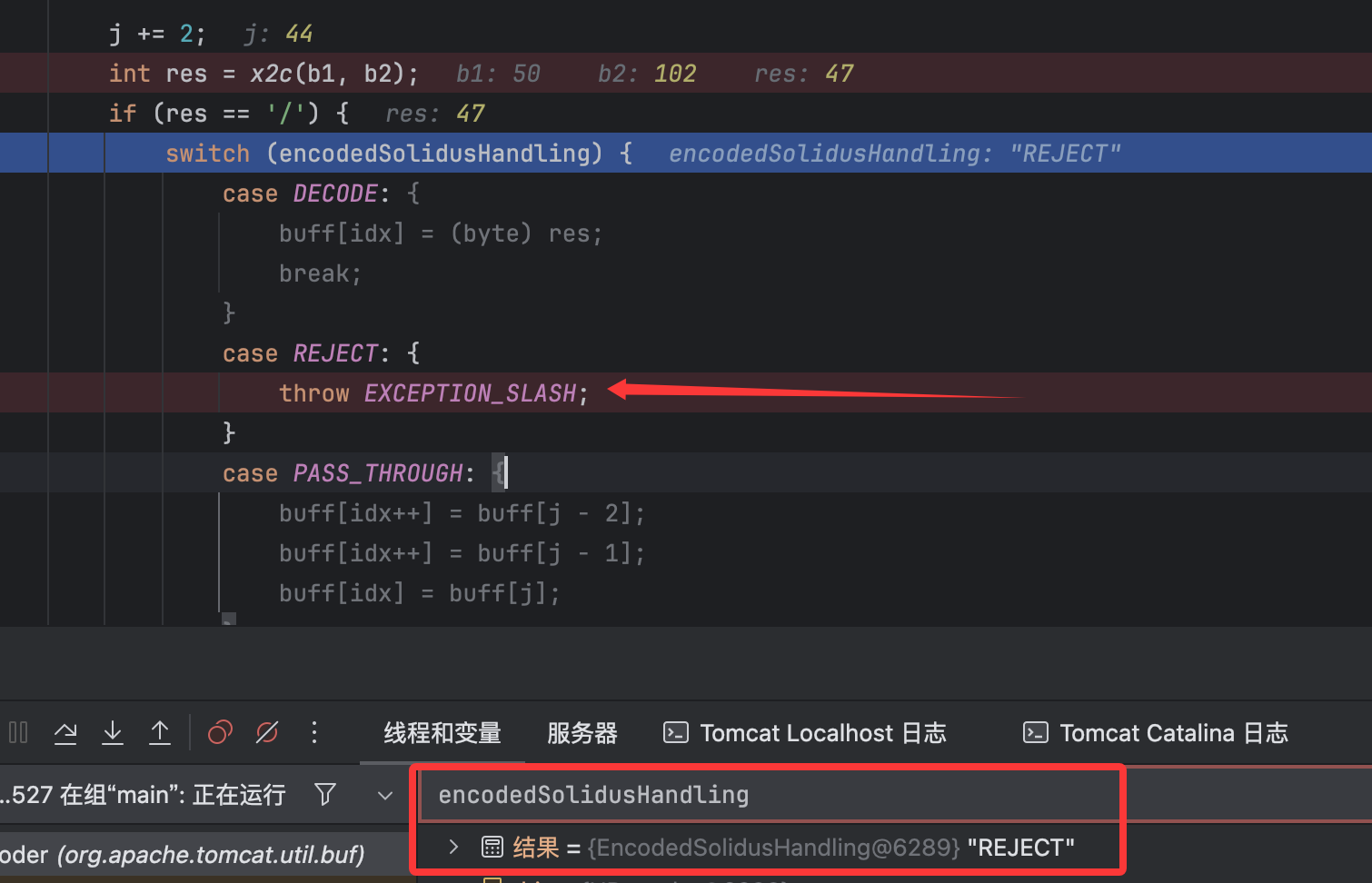
在默认配置下,如图所示模式就是REJECT,故这里会直接抛出异常:
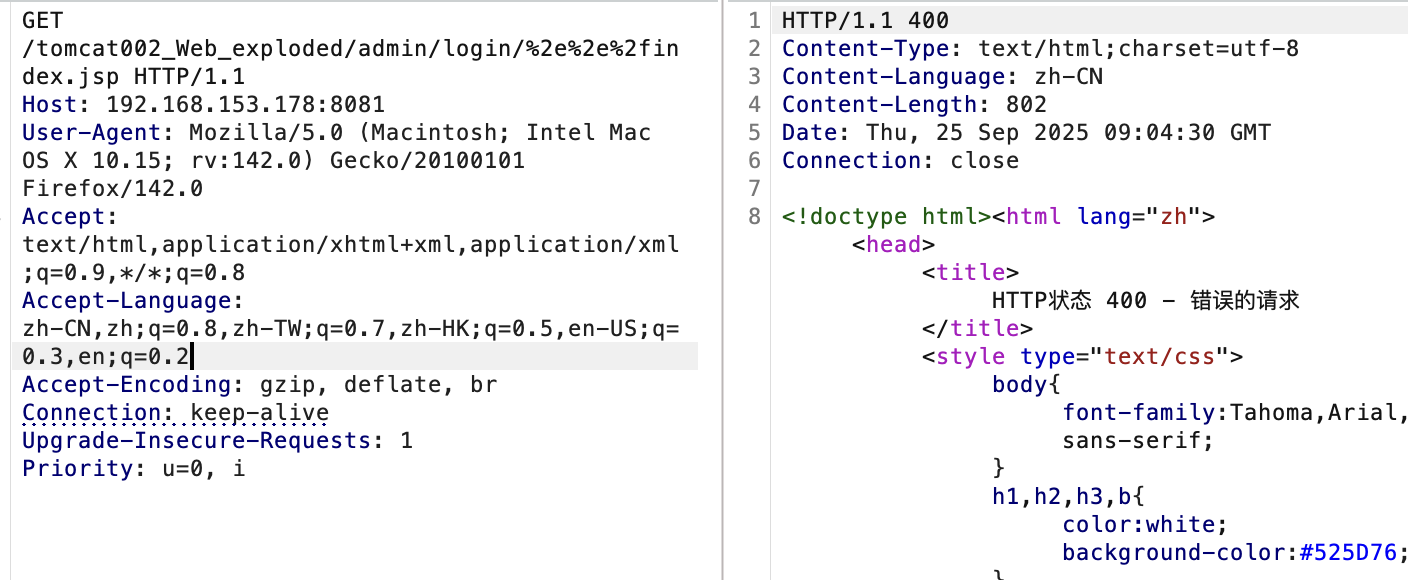
故只用编码.即可。需要注意的是:编码分号也是有问题的,主要原因就是解析顺序的问题,在前面就提到了顺序为:
由此可以知道整体的逻辑就是 先url解码=>去除分号及其匹配的键值对 => 去掉./ =》去掉../以及前一个目录。
如果编码了分号,那么在第一步就会因为没有匹配到分号而不能正常删去uri上的键值对,导致后续的所有操作的不能生效。
——————————
最后
那么如何修复呢,其实直接使用getServletPath()方法来进行判断即可,后端简单改一下代码来对比:
1
2
3
4
|
String requestURL0 = req.getRequestURI();
System.out.println(requestURL0);
String requestURL = req.getServletPath();
System.out.println(requestURL);
|
然后再打前面的绕过payload,效果如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
1./tomcat002_Web_exploded/admin/login/../index.jsp未绕过,获取内容为:
/tomcat002_Web_exploded/admin/login/../index.jsp
/admin/index.jsp
2.
/tomcat002_Web_exploded/admin/login/..;a=b/index.jsp未绕过,获取内容为:
/tomcat002_Web_exploded/admin/login/..;a=b/index.jsp
/admin/index.jsp
3./tomcat002_Web_exploded/admin/login/%2e%2e/index.jsp未绕过,获取内容为:
/tomcat002_Web_exploded/admin/login/%2e%2e/index.jsp
/admin/index.jsp
|
可以看到获取到的内容都是对应的servlet路径,成功实现限制,如有问题,敬请指正。
————
这一部分的绕过方式还是很多的,关键在于后端代码是如何实现的,还有的就是对代码层面的理解以及对url的处理逻辑。如何可以挖掘出这样一个框架下的权限绕过漏洞,个人认为需要如下几点:
- 清楚框架的整体对http请求的处理结果
- 对关键信息的敏感性
- 后端代码实现的逻辑错误
整体缺一不可,需要一定的技术深度,这个权限绕过漏洞确实经典。
参考文章:
https://tomcat.net.cn/tomcat-11.0-doc/index.html
https://xz.aliyun.com/news/7139
https://www.cnblogs.com/zpchcbd/p/14815501.html